Source copy, Databricks and Apache Airflow 2.0 (Release 4.2.4)
June 20th, 2021

We’re back with a new release, and it is stuffed with new features.
We added support for Databricks, we updated our Flow Management connector to work with Apache Airflow 2.0. Also, VaultSpeed users can now copy an entire source configuration. These, and many more changes, come with VaultSpeed R4.2.4!
Databricks
Run your Data Vault in the Databricks data lakehouse!
You are now able to generate and deploy Spark code to Databricks and run it with Airflow. The deployment will create Spark SQL notebooks in Databricks for all your Data Vault mappings. Airflow will launch those jobs, running the Notebooks. Integration with Azure Data Factory is coming soon.
The target Database type is still Spark, but the ETL generation type has to be set to Databricks SQL.

Airflow 2.0
Apache Airflow 2.0 brings a truckload of great new features like a modernized user interface, the Airflow API, improved performance of the scheduler, the Taskflow API and others. VaultSpeed now supports Airflow 2.0. The VaultSpeed plugin for Airflow and all generated code have been reworked. All code will still work for previous Airflow versions. Just like before, once you’ve installed our plugin into your Airflow environment, Airflow becomes VaultSpeed aware. You’re able to generate and deploy workflows and run all the code needed to load your Data Vault.
Copy Sources
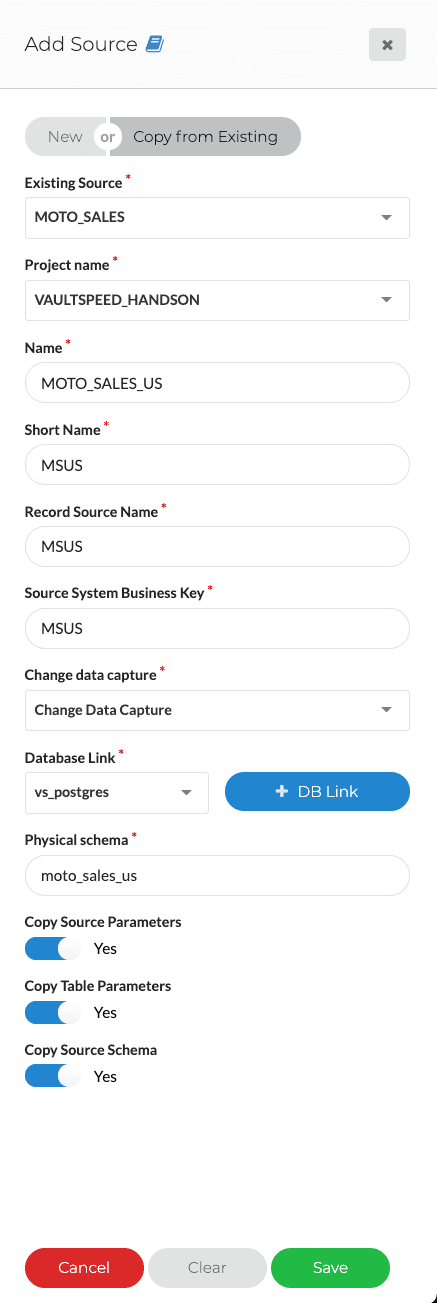
Users will also have the ability to copy existing sources. In some cases, an organization will need to integrate multiple sources that share a lot of similarities between them.
To give an example: Company ABC has the same version of their Sales CRM running in both Europe and the US. The only difference is that they have a few additional modules activated in the US.
Using the source copy functionality, they can now copy the entire source configuration from EU Sales to US Sales. All you need to do is identify and configure objects or settings that are specific only for the new source, but you can now skip all similar configuration you had already done for the EU source.
Using this functionality can obviously save a lot of time when integrating similar sources into your Data Vault model.
User Experience Improvements
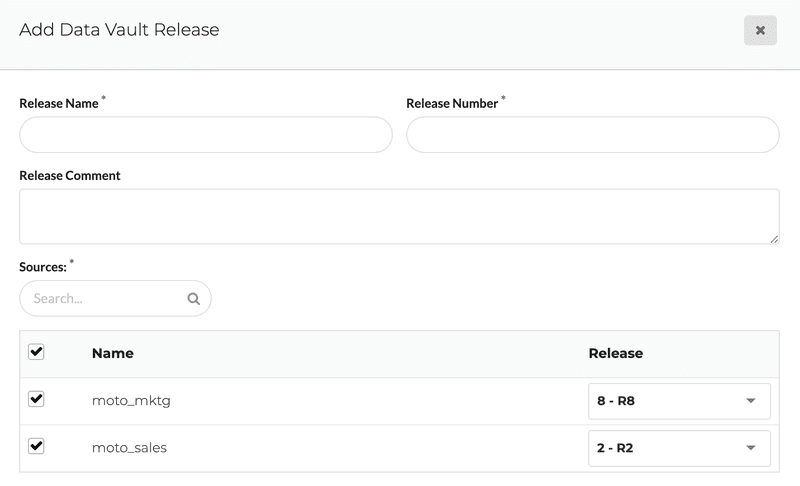
The new release comes with a few other changes like a better screen to create a new data vault release. It has become a lot easier to indicate which version of which sources you would like to include in a specific data vault release. You can also choose to exclude certain sources from your release.
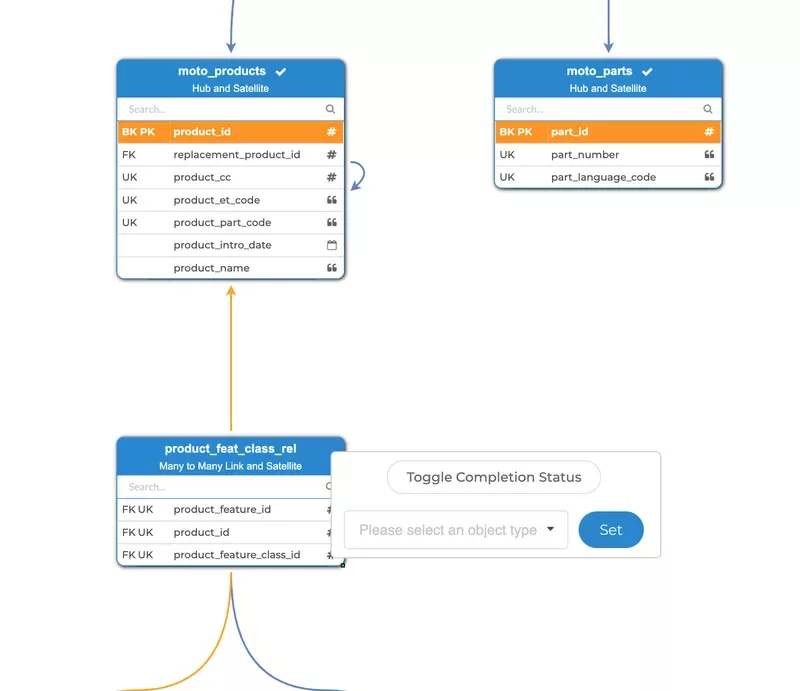
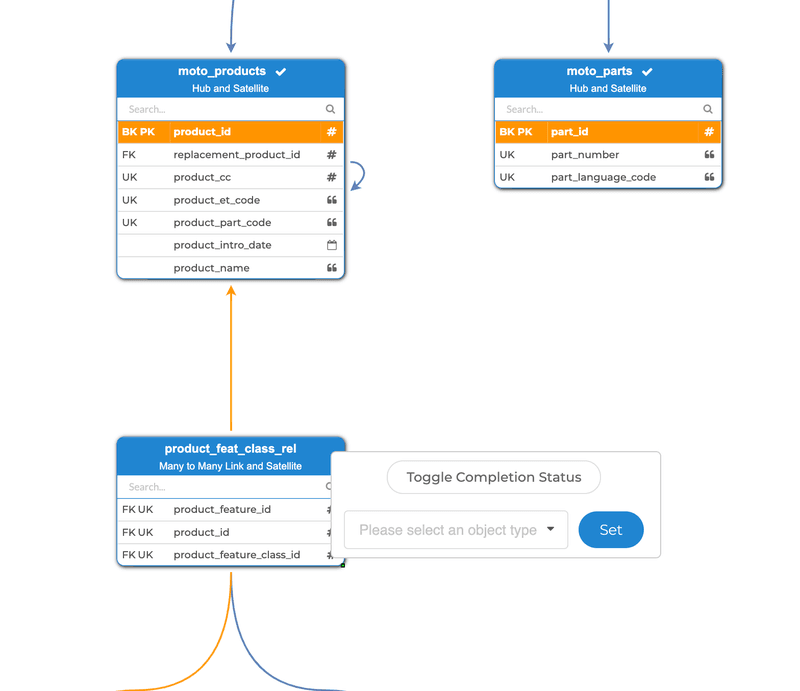
We also made it possible to mark objects in the source editor as completed, the completed objects will be highlighted in green. This status can be toggled by right-clicking on an object. The selection page can filter out completed objects, and there is also a button to remove all completed objects from the canvas. This allows you to track progress in your source modelling and get things organized.
Business Keys
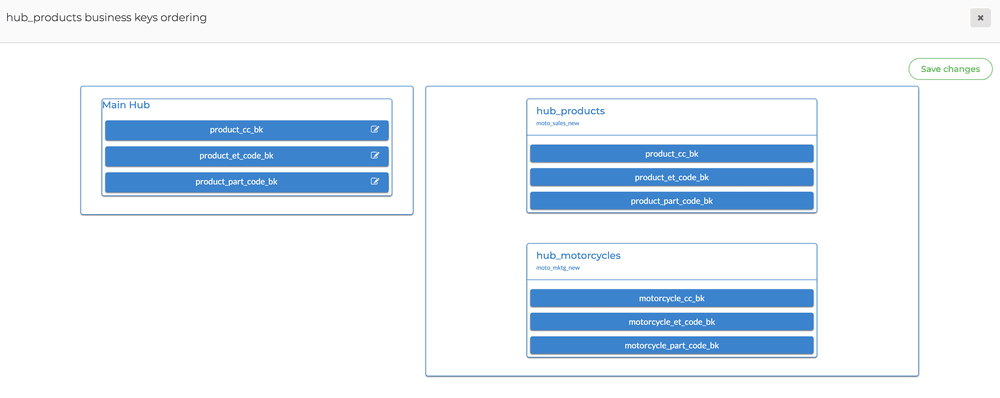
We made it easier to change and re-order business keys in the Data Vault. We added a new screen where for each hub group the business keys of the grouped objects can be renamed and reordered, and the business keys of the hubs in the group can be reordered to match. So the keys in the different sources can now have different orders and names and still result in the same hash key calculation.
We added similar ability to reorder the linked hubs in many-to-many links ( and non historized links). In a separate screen, you can change the order of the HUB’s included in a many to many link or non-historical link.
Other changes
- We renamed the “build flag” property to “ignored” everywhere in the application.
- Added extra template variables for the custom deploy scripts in the agent, instead of only the zip name, you can now also get the generation id, the generation info, and the generation type, similar to the git commit message functionality. Example: deploy.cmd = sh C:\Users\name\Documents\agent\deploy.sh {zipname} {code_type} ”{info}”
- The compare functionality in the source graphical overview will now skip ignored releases. This means that it will compare with the last non ignored locked release before the current one.
- We added support for overlapping loading windows to the Azure Data Factory FMC, this can be configured by using the following parameters: FMC_OVERLAPPING_LOADING_WINDOWS, FMC_WINDOW_OVERLAP_SIZE, FMC_WINDOW_OVERLAP_TYPE.
- The metadata-export has been converted to a task, this is done to support exporting data for very large Data Vaults. Before the export would time out and not return a file if it takes too long.
More releases are coming!