Resources
VaultSpeed is engineered for ambition. Want to find out more about automated data transformation, follow trainings or meet like-minded professionals?
Articles
A Robust Foundation for Data Products

Articles
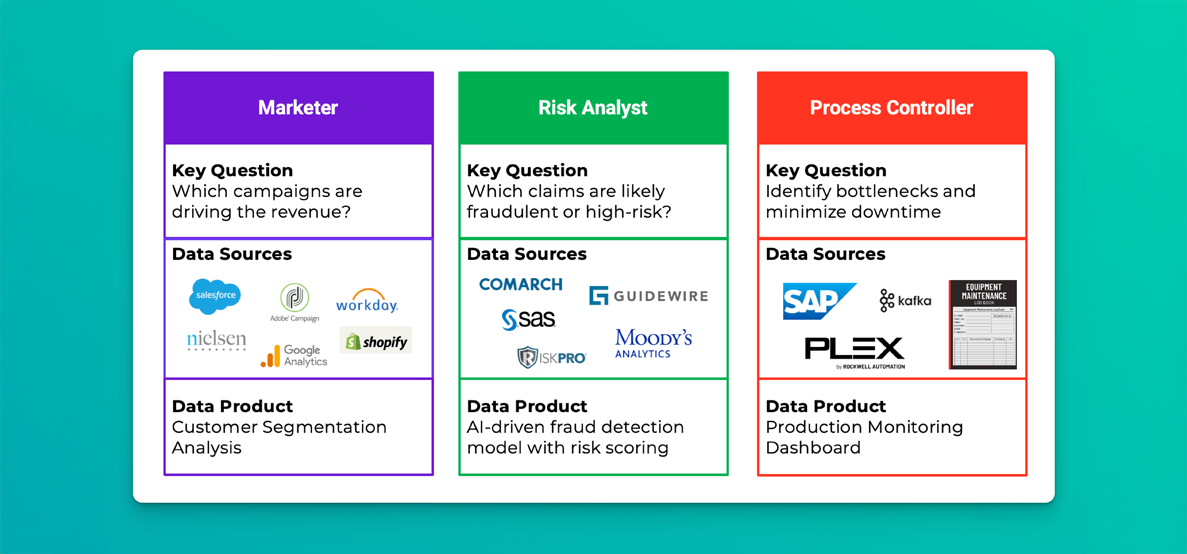
Who Benefits from Good Data Models? (Hint: Everyone on your data team)
Articles
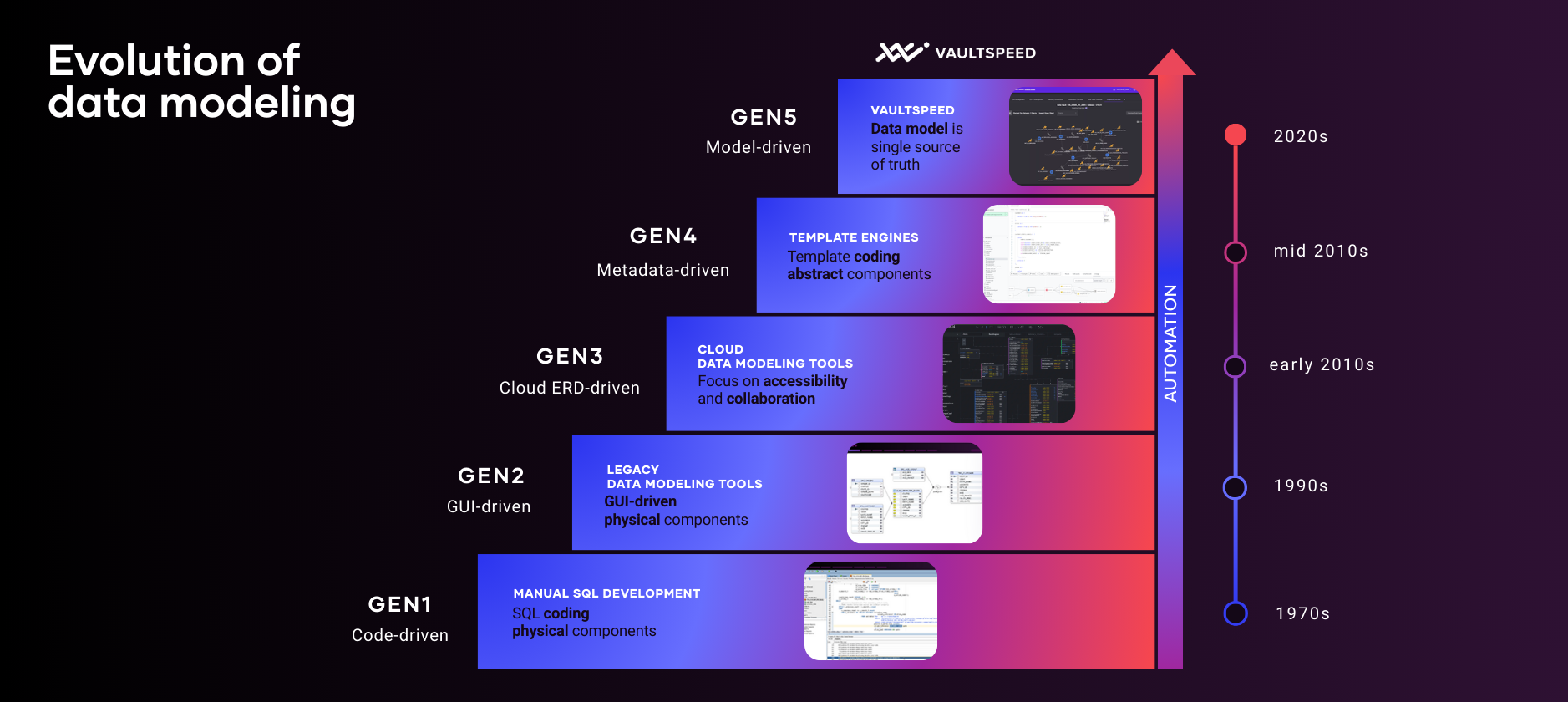
The Evolution of Database Modeling
Articles
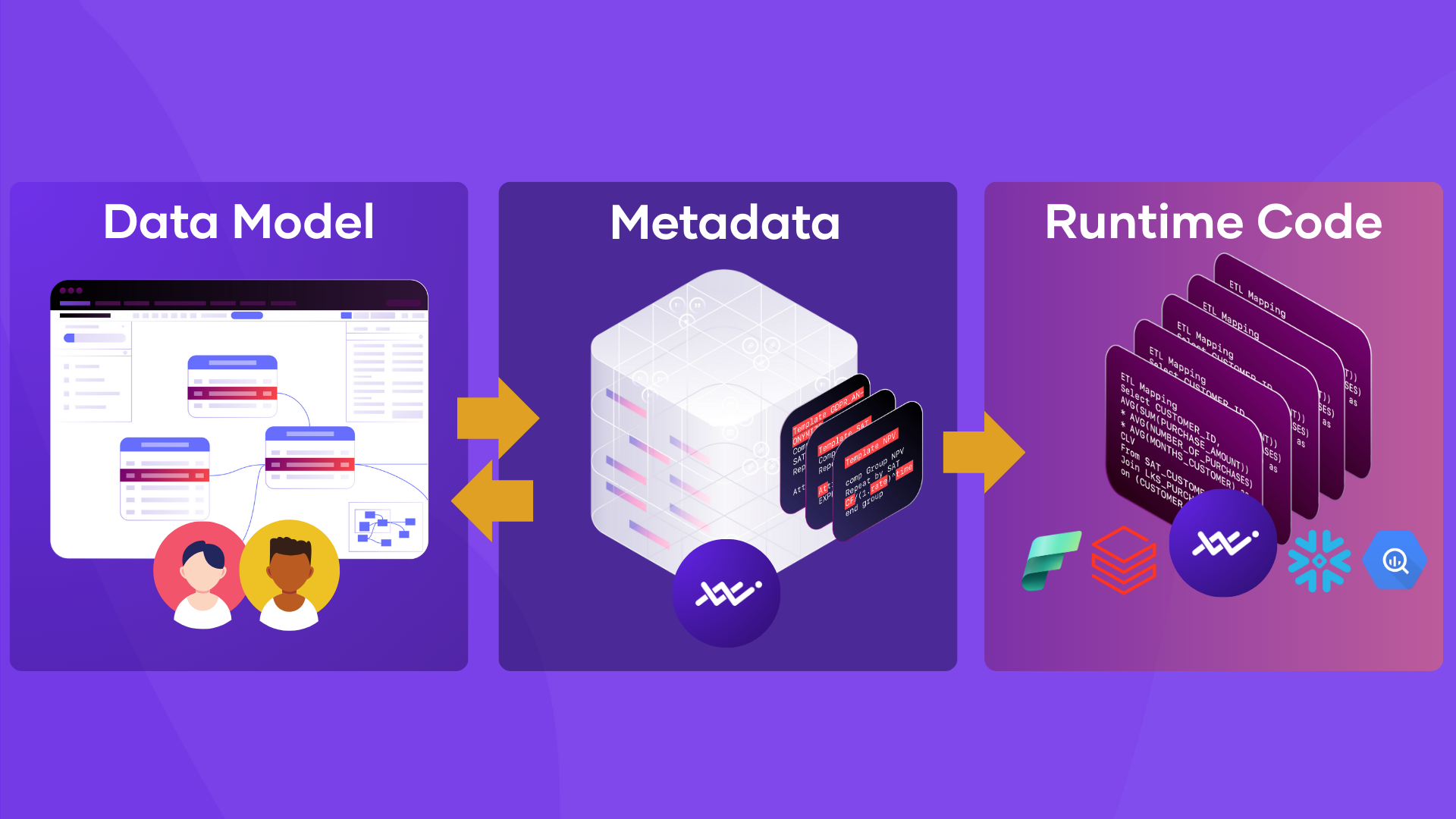
Escaping the maintenance trap: why model-driven automation beats template sprawl

Webinars
On demandEU/US
Fabric Flashback, a LinkedIn Live with Falke Van Onacker, Jonas De Keuster and Ian Clarke

Articles