Built for data teams, trusted by the business
With VaultSpeed, models carry business meaning all the way to production, delivering governed pipelines engineers trust and business leaders rely on.


Agents grounded in your enterprise context store
Every step of building, modeling, and shipping data is an agent skill you can call by name. Agents reason over your enterprise context store and contracts. They propose changes for human review, and ship only what you approve, with versioning, lineage, and policy attached to every decision.
Visual data modeling to activate your metadata
Canvas is where business and data teams model together. From conceptual models to source mappings, Data Vault structures, and physical pipelines, every layer stays connected as active metadata — carrying business intent into production and providing a trusted foundation to ground AI in consistent, governed meaning.

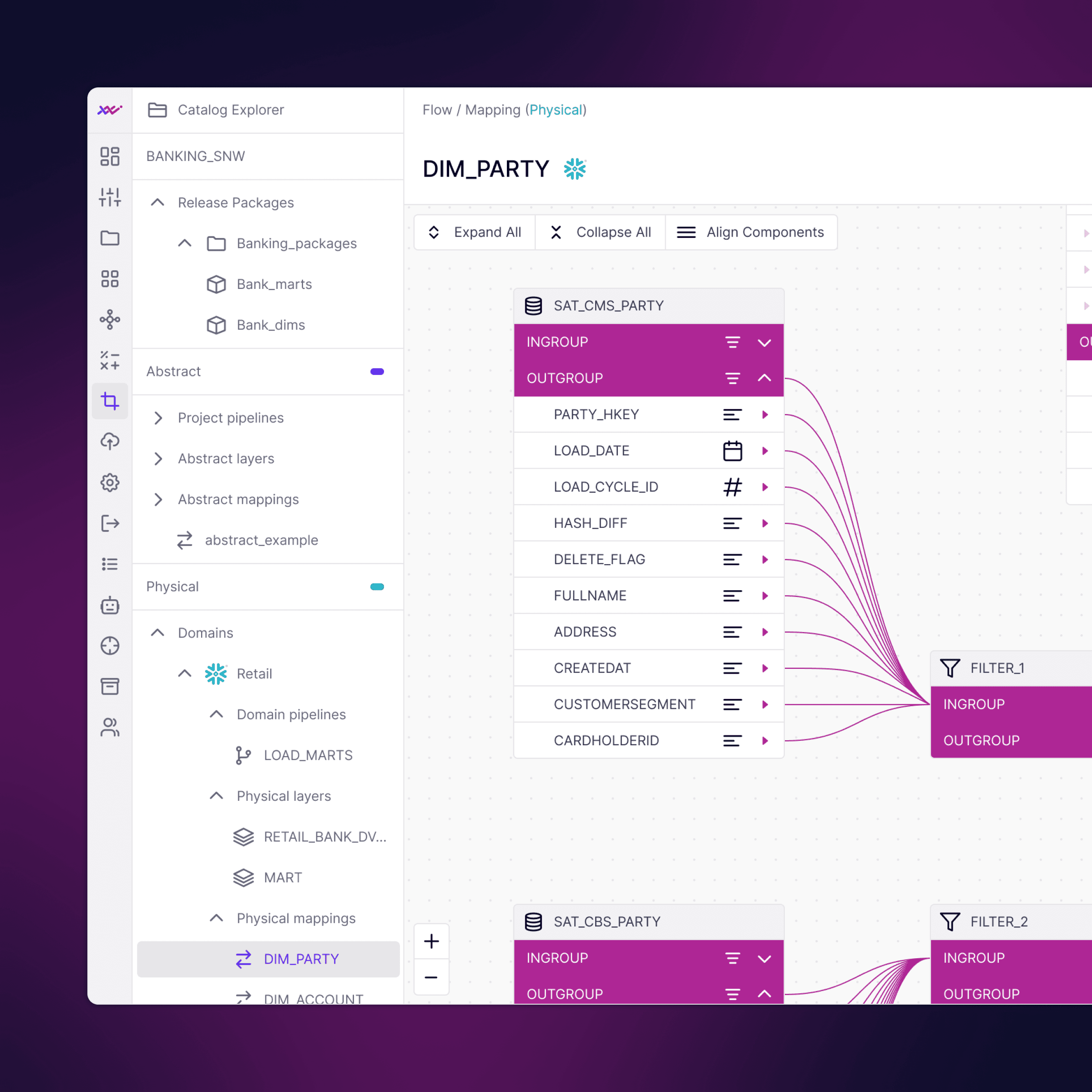
Governed transformation for the Gold layer
Once models are validated in Canvas, Flow turns them into governed transformations and pipelines, because nobody should code a data vault anymore. With automation patterns and delta-only code generation, it produces deterministic, production-ready SQL/dbt you own, deployable natively in Snowflake, Databricks, BigQuery, Redshift, and Fabric, with no runtime lock-in.
Runtime-free deployment native to your cloud platform
Nobody needs yet another catalog. VaultSpeed Connect lets you extend, not replicate. Every model, pipeline, and change is accessible through secure APIs, SDKs, Git integration, and open standards like MCP, so you can push automation into catalogs, CI/CD, orchestration, and AI agents, all under enterprise governance.

