Automated workflows for Apache Airflow
September 16th, 2020

Data Warehouse Automation is much broader than the generation and deployment of DDL and ELT code only. One of the areas that should also be automated is run and monitoring. In this area, VaultSpeed chose to integrate with Apache Airflow. Airflow is one of the most extensive and popular workflow & scheduling tools available. VaultSpeed generates the workflows (or DAGs: Directed Acyclic Graphs) to run and monitor the execution of loads using Airflow.

Introduction
The ultimate goal of building a data hub or data warehouse is to store data and make it accessible to users throughout the organisation. To do that you need to start load data into it. One of the advantages of Data Vault 2.0 and the use of hash keys in particular is that objects have almost no loading dependencies. This means that with Data Vault, your loading process can reach very high degrees of parallelism.
Another advantage is that data can be loaded at multiple speeds. You might want to load some objects in (near) real time. Hourly, daily or even monthly load cycles might be satisfactory for other data sources.
In every case, you need to set up the workflow to load each object. And you need to be able to schedule, host and monitor this loading process.
In this article we will explain how to leverage automation for another important part of the data warehouse: develop, schedule and monitor your workflows.
VaultSpeed setup
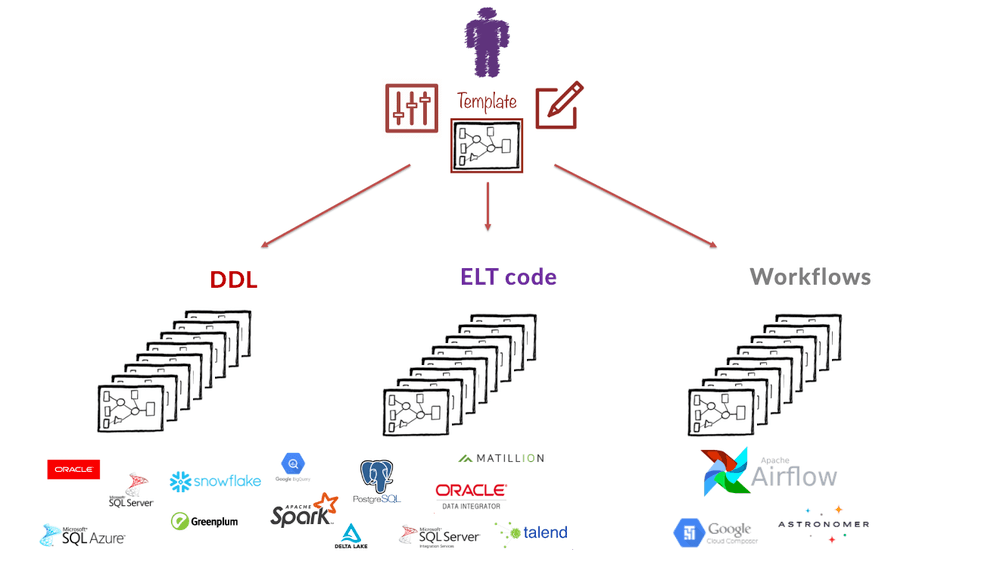
VaultSpeed generates DDL and ELT code for your data warehouse, data hub, etc. Once deployed on the target environment, these components form the backbone of your data ingestion process. The next step is to organize these objects into a proper workflow and build proper Flow Management Control.
Parameters
The first step in this process is to set up some parameters within VaultSpeed. This setup will influence how the Airflow DAGs are built:
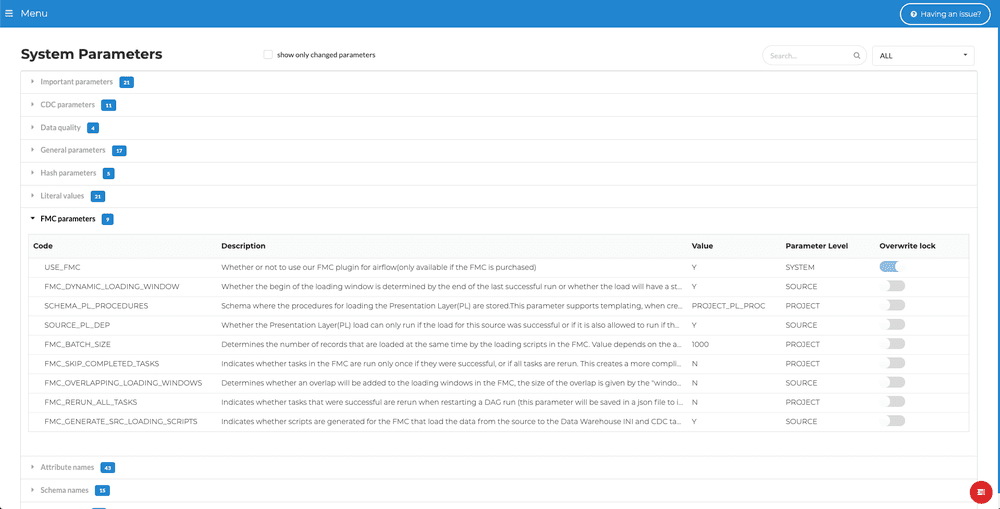
- USE_FMC: Whether or not you use Flow Management Control, this will cause some extra objects to be generated with your DDL.
- FMC_DYNAMIC_LOADING_WINDOW: You can choose whether the beginning of the loading window is determined by the end of the last successful run. Alternatively, you can choose that the load will have a static loading window but will wait for the successful execution of the previous run.
- SCHEMA_PL_PROCEDURES: Schema where your Presentation Layer procedures are stored. This is used when generating code for loading the PL.
- FMC_GENERATE_SRC_LOADING_SCRIPTS: If enabled, extra tasks will be added to the generated workflow that will transfer data from your source system to the data warehouse.
- FMC_SKIP_COMPLETED_TASKS: In case of an error you need to restart your load. This parameter indicates whether tasks in the FMC are run only once if they were successful, or if all tasks are rerun upon restarting.
- SOURCE_PL_DEP: This parameter determines whether the load of the Business Vault & Presentation Layer should wait for the load of a source to be successful or simply completed.
Add workflows
Once you have set up the parameters it's time to generate Airflow code. You’ll find all the workflows and setting in the Flow Management Control screen. Adding an FMC workflow is quite easy:
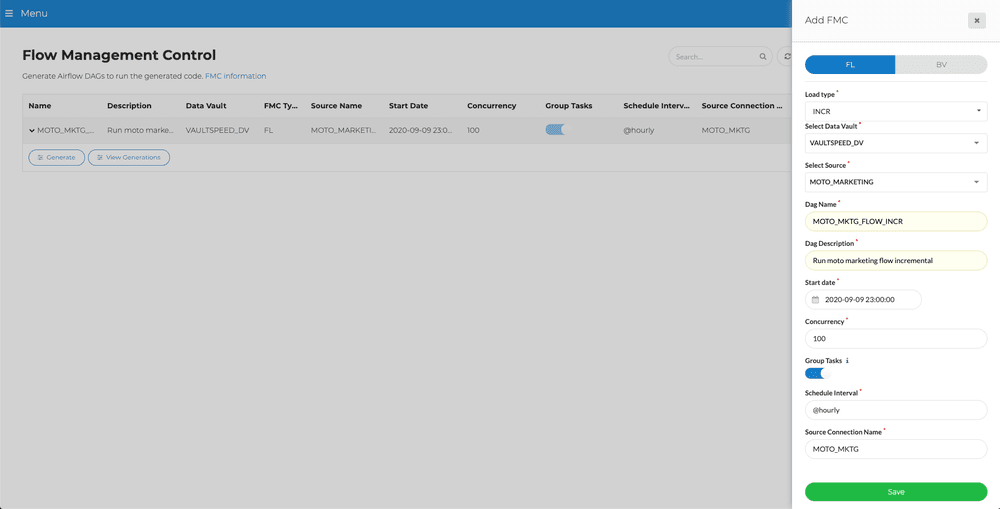
You can generate flows for your Raw Data Vault or Business Data Vault.
You have to select a load type, Data Vault type and one of your sources. VaultSpeed always builds a single flow for a single source. You can add dependencies between them in Airflow.
Choose a DAG name (DAG is the name Airflow uses for a workflow). This name should be unique to this workflow e.g. <dv name>_<source name>_<load type>. Each DAG should also have a description.
We also offer a feature to enable task grouping. When using SQL code and mini batches, this reduces the overhead of creating connections to the DB. So if connecting takes a lot of time compared to actual mapping execution, enabling this option should save you some load time.
Choose a start date, this is the date and time at which your initial load will run, and the start of your first incremental load window.
By setting the concurrency, you can indicate how many tasks in this workflow are allowed to be executed at the same time. This depends on the scalability of the target platform and the resource usage (CPU) of your airflow scheduler and workers (can easily be changed later).
Finally you enter a name for your source and target database connections. These connections will be defined in Airflow later.
When you choose the incremental flow type, you need to set a schedule interval. This is the time between incremental loads. This can be:
“@hourly” : run once an hour at the beginning of the hour
“@daily” : run once a day at midnight
“@weekly” : run once a week at midnight on Sunday morning
“@monthly” : run once a month at midnight of the first day of the month
“@yearly” : run once a year at midnight of January 1
cron expression:(e.g. “0 0 * * *”)
python timedelta() function (e.g. timedelta(minutes=15))
Generate code
To generate code for a workflow, you need to pick a version of your generated ELTs. Select the one for which you want to build your workflow. Hit “Start Generation” to launch generation of the code.
A few files will be generated in the back end, the first being a python script containing the actual DAG. Also some JSON files are added containing the rest of the setup.
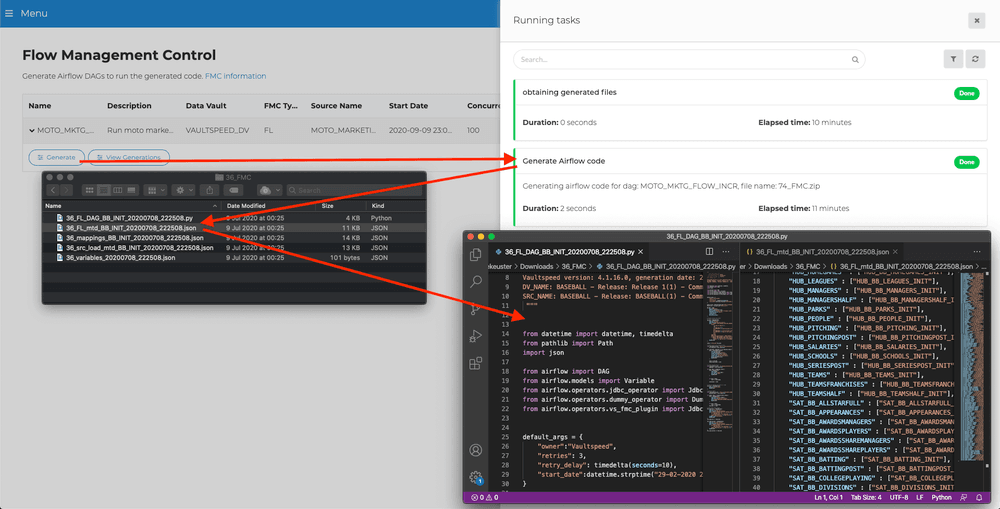
You can always look at previous workflow generations, their settings at that time, the Data Vault and source release, when they were generated and the name of the zipfile containing the generated python code.
Airflow Setup
To get started with Airflow you need to set up a metadata database and install Airflow. Once you have a running Airflow environment you need to finish the setup. Our VaultSpeed FMC plugin for Airflow does most of this for you.
After setting up database connections and adding some variables you can import your newly generated DAGs. You can do this manually, but of course automated deployment from VaultSpeed straight to Airflow (or through a versioning system) is also possible.
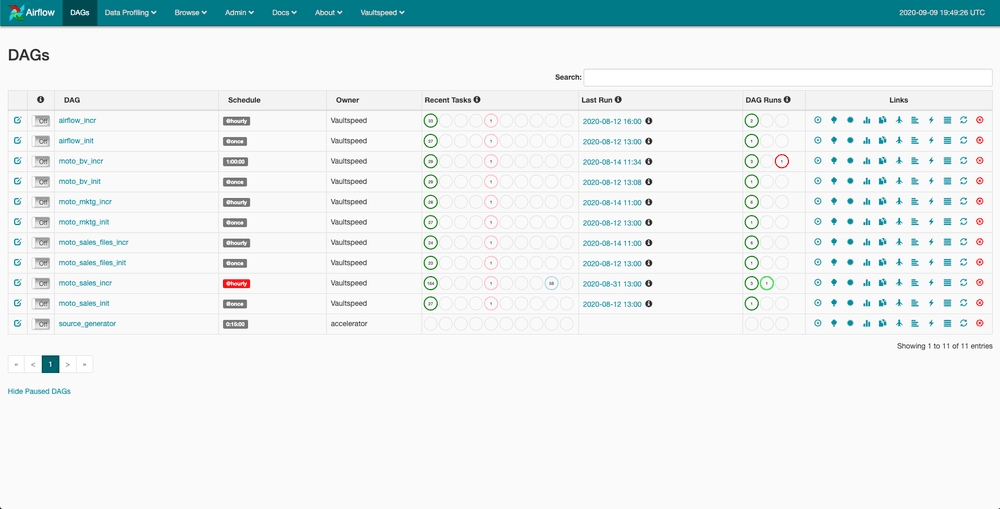
To start executing loads, start the scheduler and the workers.
When you unpause the freshly imported workflow, your DAG will start running.
Current day and time need to be later than the start date in the case of the initial load. The incremental load will start after start date + interval.
The picture below shows the DAG we generated in this example. You can clearly see we used the grouping function as it has grouped tasks into four parallel loading sets per layer.
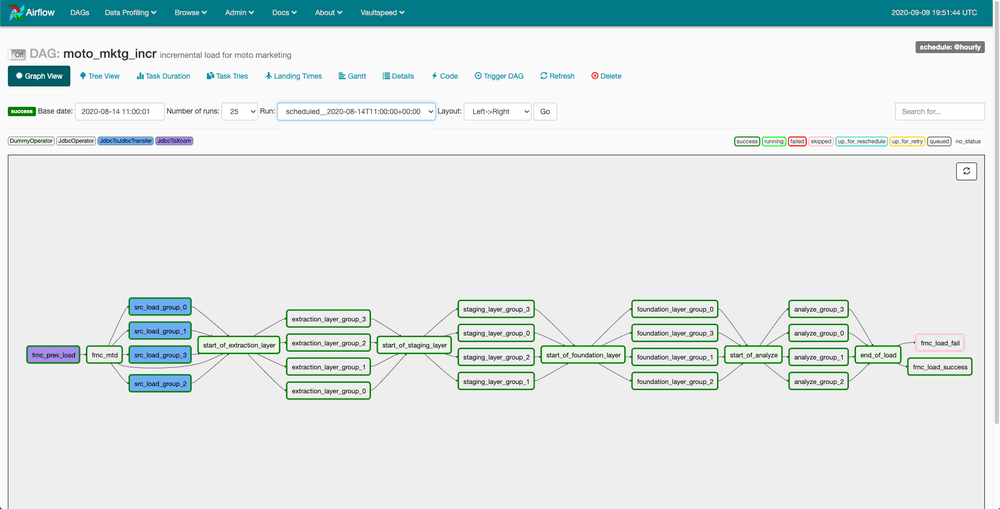
Airflow offers an intuitive interface in which you can monitor workflows, view logs and more. You can get a good overview of execution times and search for outliers. Upon failure you can inspect logs of separate tasks and start debugging.
Conclusion
Building a data warehouse, data hub or any other type of integration system requires building data structures and ELT code. But those two components are useless without workflows. You can build them manually, but VaultSpeed offers a solution that is less time consuming and more cost effective.
Automation in VaultSpeed is not limited to code generation and deployment. VaultSpeed also automates your workflows. When considering a standard workflow solution, Apache Airflow is our tool of choice.
About Apache Airflow: This is very well established in the market and is open source. It features an intuitive interface and makes it easy to scale out workers horizontally when you need to execute lots of tasks in parallel. It is easy to run both locally or in a (managed) cloud environment.
With a few steps, you can set up workflow generation, versioning and auto-deployment into your Airflow environment. Once completed, you can start loading data.
VaultSpeed’s FMC workflow generation is sold as a separate module in addition to the standard environment. It targets clients looking for a proper solution to organize workflows in their integration platforms. More details on pricing for this automation module are available upon request.