As data becomes more central to every product, team, and decision, organizations are struggling to balance two competing forces: the need for agility and the need for control. Traditional data warehouse architectures are rigid and expensive to change - the complexity between sources, the incoherence of the model - all factors that make it hard for the data team to adapt and scale. This is where Data Vault stands out.
Designed specifically for agility in enterprise environments, Data Vault is an approach to data modeling that empowers teams to build scalable and flexible data platforms. In this article, we’ll cover what Data Vault is, why it matters, and how it solves specific data challenges.
The Bull Case for Data Vault


What is Data Vault?
Data Vault is a hybrid data modeling technique that was developed by Dan Linstedt in the 1990s to solve a major challenge: how to build data warehouses that are flexible, scalable, and audit-friendly in rapidly changing enterprise environments.
Where traditional data models aim for immediate usability (like reporting), Data Vault is designed for:
- Integrating data from multiple, inconsistent sources
- Capturing historical changes in data over time
- Adapting quickly to source system changes
- Providing traceability and auditability of all changes
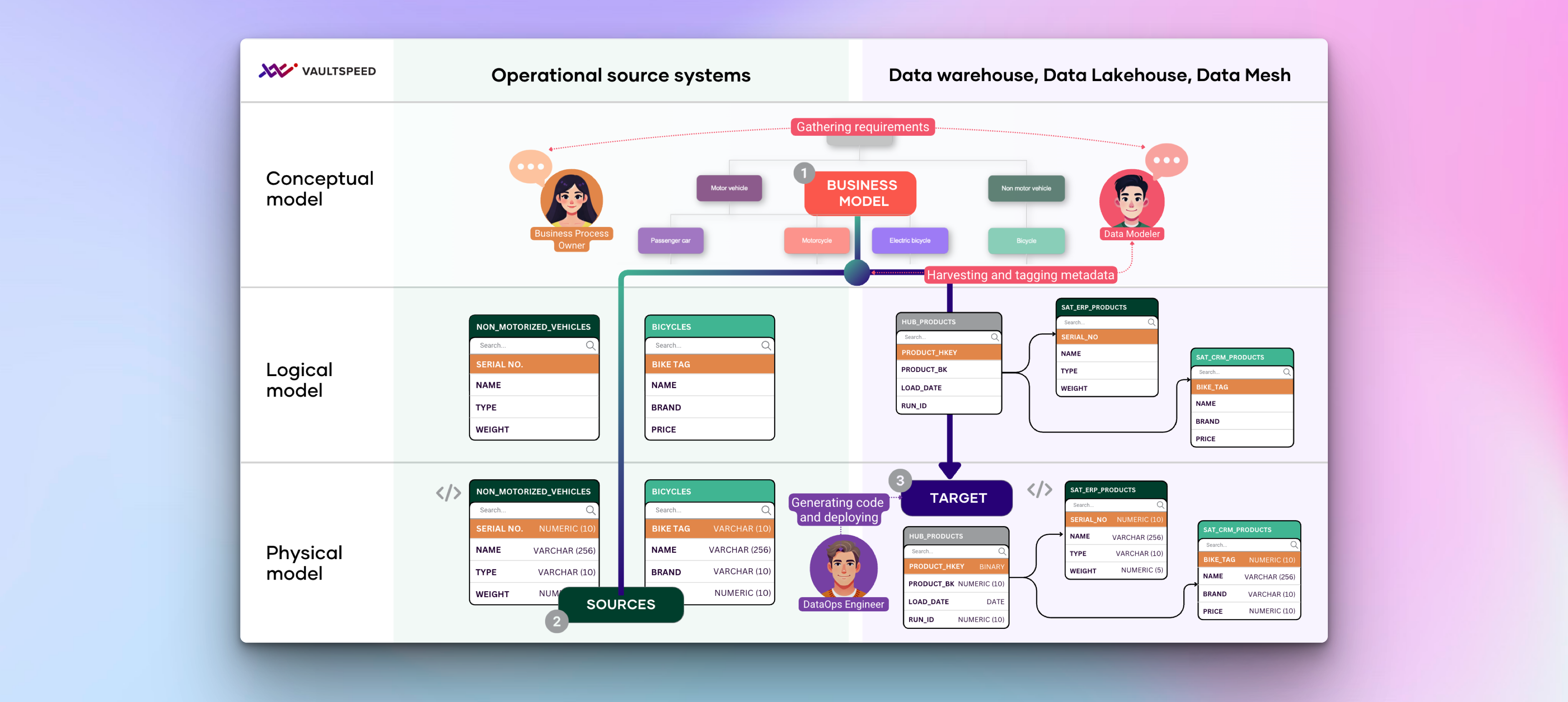
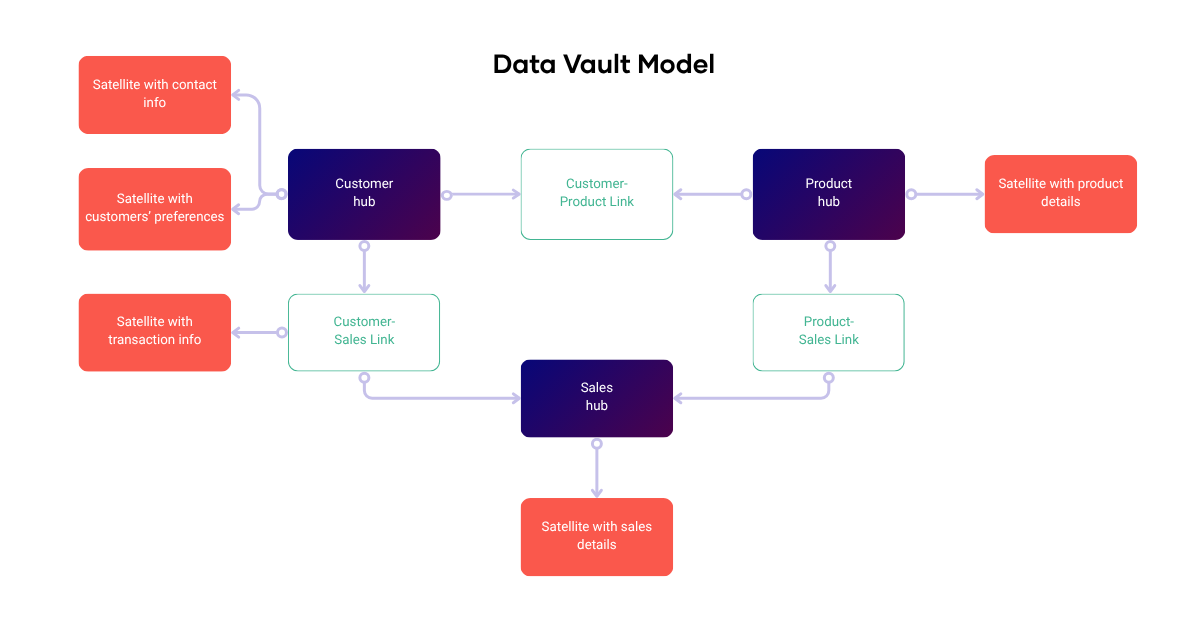
At a high level, it has 3 object types - hubs, links, & satellites. They’re the building blocks that separate business keys, relationships, and descriptive data.
- Hubs:represent core business entities like Customers, Products, or Orders. They usually only contain the business key and metadata like load state and source.
Example: ‘hub_customer’ with fields like ‘customer_id’,’load_date’, ‘record_source’ - Links: define relationships between hubs (e.g. a Customer places an Order)
Example: ‘link_customer_order’ links ‘hub_customer’ to ‘hub_order’ - Satellites: store the descriptive and historical information related to hubs or links. These are fully historized - capturing every change to every attribute over time.
Example: ‘sat_customer_details’ with fields like first_name, email, address, effective_date, load_date
This separation enables:
- Scalability: by isolating change in satellites, you avoid full-model rewrites
- Auditability: all changes are historized and traceable
- Adaptability: new source systems or attributes can be added without breaking the model.
Why Not Just Use Star Schemas?
Star schemas and dimensional models are great for analytics and reporting - they’re simple, performant, and optimized for answering business questions quickly. But relying only on star schemas has trade-offs:
Star Schema:
- Is optimized for fast reporting
- Is hard to evolve when source systems change
- Has limited audit/logging capability
Data Vault:
- Optimized for integration, agility, and history tracking
- Easy to adapt to new sources or changing structures
- Built-in history tracking and auditability
The key takeaway isn’t Data Vault vs Star Schema - it’s that you shouldn’t just use one or the other. In a modern architecture, you ideally use both:
- Data Vault to integrate, historize, and future-proof your raw data
- Star Schemas to reshape that data into a fast, user-friendly schemas for analytics
Think of the Data Vault as the foundation - clean, consistent, and flexible - and star schemas as the floorplan - designed for specific use cases. With this layered approach, your data platform becomes both robust and responsive: audit-ready, change-resilient, and still easy to use.
Why Data Vault Matters
Data Vault addresses 3 problems data teams face when building DW data products:
1. Scalability
As data volumes and sources grow, so does the complexity of managing them. Data Vault scales horizontally, so you can ingest new data without remodeling the entire DW.
Example: A logistics firm adding thousands of IoT devices can simply append new satellites to existing hubs, without altering relationships or historical records.
2. Adaptability to Change
Business requirements evolve as the business evolves. Traditional models struggle when source systems change, but with Data Vault, you isolate change to satellites, enabling you to adapt without downtime. With a traditional schema, a small change (like a new column in a source or a new data source altogether) could force a cascading remodel of tables and ETL. Data Vault decouples things so well that you can integrate new data without disrupting what’s already in place. If a new operational system comes along, you add new hubs (for its business keys), links (to connect to existing hubs), and satellites (for its attributes). This doesn’t require refactoring the old schema or touching the historical data - the vault is built to absorb change. Likewise, if a source’s structure changes (say a column is added or a code value changes), you can add a new satellite or record the change in the existing satellite with a new timestamped row. The Data Vault embraces schema evolution. This adaptability means faster response to business changes. In short, DV is agile - allowing the data warehouse to evolve incrementally rather than undergo painful redesigns for every new requirement.
Example: A marketing team adds a new social media platform (e.g. TikTok) to its data mix. Instead of redesigning the customer schema, a new satellite is added to the existing Customer hub.
3. Efficiency Through Automation
Data Vault’s standardized, modular design leads to efficiency in development and maintenance. All hubs follow the same pattern, as do all links and all satellites - this consistency enables a high degree of automation in building out the warehouse. Many teams use tools like VaultSpeed to automate hub, link, and satellite creation. This reduces manual work and accelerates delivery. This means engineers spend less time hand-coding ETL for each new table and more time on value-add logic. In addition to efficiency, it also improves information sharing and maintainability. Since the model uses common components and naming conventions, team members can more easily understand the model.
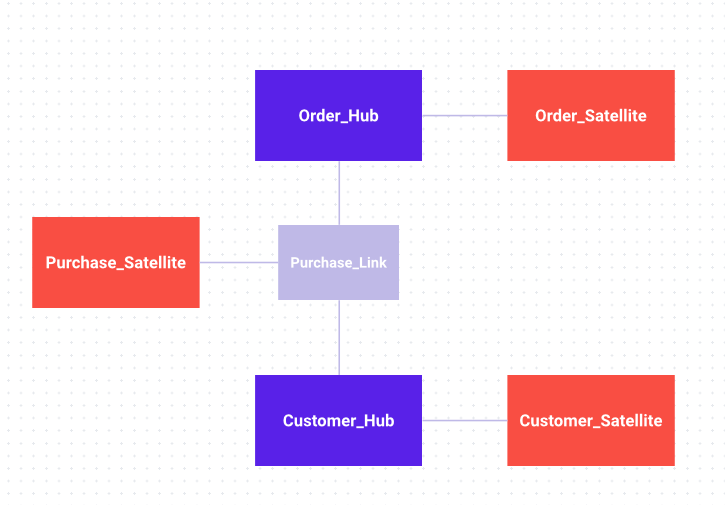
Real-World Example: Retail Data Product
- Hub_Customer: Stores unique ‘Customer_ID’
- Hub_Product: Stores ‘Product_ID’
- Link_Purchase: Joins Customer and Product hubs via ‘Transaction_ID’
- Satellite_Customer_Info: Contains name, address, and email
- Satellite_Purchase_Detail: Stores time, quality, and payment method
Now let’s do a more nuanced example: Integrating marketing and sales data
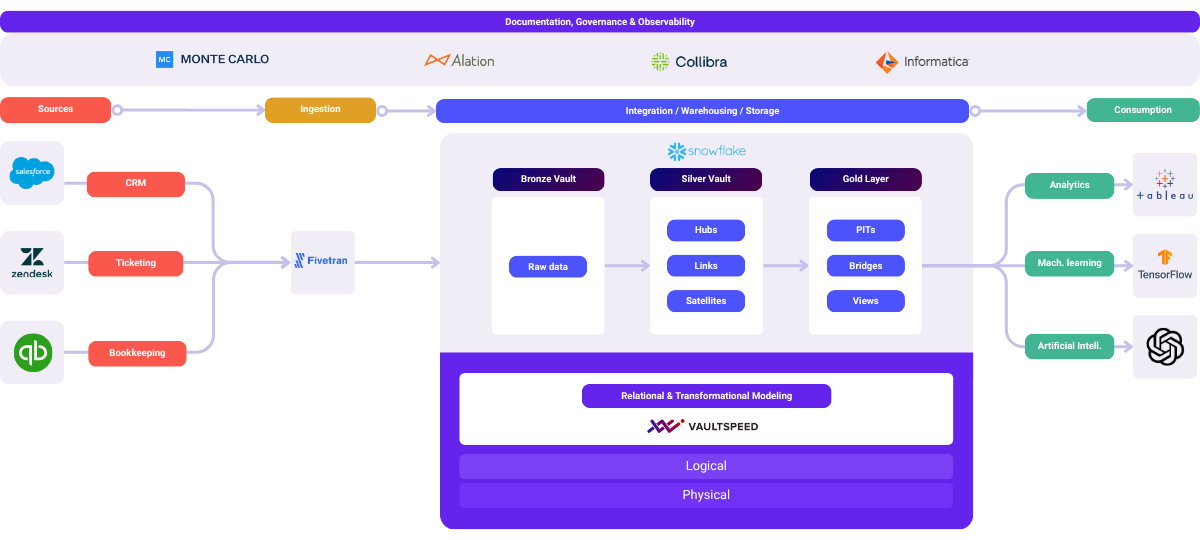
To illustrate how Data Vault works in practice, let’s walk through a simplified real-world scenario. Imagine a company wants to integrate data from multiple source systems - for example, a sales database and a marketing platform - to build a unified view of customer activity. The sales system contains transactions (who bought what, when, for how much), and the marketing system contains information on campaigns and customer outreach (who was targeted, responses, etc.) In a traditional model, combining these would either involve creating a complex single schema or building pipelines to a common data lake and then cleaning and joining data for each use case. With Data Vault, we can seamlessly bring these together while preserving all the history.
First, we identify the key business entities (the business keys) in this domain. Obvious ones are Customer, Product, Campaign, and Sale. In Data Vault, each of these becomes a Hub. We create a Customer Hub storing unique customer IDs, a Product Hub for product IDs, a Campaign Hub for campaign IDs, and a Sales Hub (if we treat each sale as an identifiable business object - alternatively, Sale could be modeled as a link between Customer and Product. Each hub will contain the list of all unique IDs from any source that references that entity. For instance, the Customer Hub will aggregate customer identifiers coming from both the sales system and the marketing system (even if one system calls it “client” and the other “user” they both map to the unified Customer hub).
Next, we model the relationships. We might have a Customer-Campaign link representing that a customer was targeted by or responded to a marketing campaign.
The satellites provide the detail from each source. For example, the sales source system might generate a sales satellite connected to a Sales hub that contains facts like quantity, price, sale date, payment method, for each transaction. There might also be a Customer satellite that provides customer info from the sales source system (e.g. customer address), and a product satellite for product attributes (name, category from the sales source system catalog). The marketing source system would also contribute its own satellites: e.g. a Customer Satellite (Marketing) that stores customer profile info or engagement scores from the marketing system, and a Campaign Satellite that stores campaign details (campaign name, start/end date, channel, etc.) attached to the Campaign Hub. It could also have a link satellite if needed (for example, a Customer–Campaign Link Satellite capturing details of each marketing touch like the response or click-through information). Each satellite is loaded from its respective source system, with a timestamp so we retain the history of changes. For instance, if a customer’s address changes in the sales system, a new row is added in the Sales-Customer Satellite with the new address and the date of change, while the Customer Hub remains the same.
With this Data Vault model, the company can now answer questions like “Which marketing campaigns did each customer see before they purchased product X?” or “What is the full history of interactions (marketing and sales) for customer xyz over time?” The beauty is that if tomorrow a new source comes long - such as a customer support system with tickets - we can integrate it easily. We may add a Support Ticket Hub and a Customer-Ticket Link, as well as satellites for ticket details and any customer info from support. This won’t break the existing model, it just extends it. The marketing and sales data vault we built remains intact and continues to operate. New queries can now leverage the support data too, by connecting through the shared Customer hub. The Data Vault ensures all data is connected via common business keys (customers, products, etc), but each source feeds its own satellites, so we maintain the lineage and original; fidelity of each source. The result is an enterprise data warehouse that is always in sync with the latest from all source systems, historically accurate, and ready to feed any number of downstream data products.
The business now has a 360-degree view of customers across sales and marketing, built on a future-proof data warehouse design.
How Data Vault Has Helped Organizations
When building data products, the model is the foundation from which everything downstream is based. But traditional methods only offer manual, non-scalable methods to build our model. With the Data Vault methodology, however, the process becomes more streamlined. It standardizes the complexity of other methods, creating “system-agnostic” models that can be automated - addressing the issue of human error, model complexity, and high maintenance costs. Here are some of the technical differences in how data is structured, modeled, and maintained in a traditional Kimball model vs a Data Vault model:
Real-world Examples:
1. Vincent McBurney, a Manager of Information Architecture & Data Modeling, from MLC Life highlights that a large organization can save anywhere from $250k to $750k up-front and $50k-$250k per month for an active Data Vault that is continuously adding new data sources.
The upfront saving comes from the following Data Vault efficiencies:
- Defining an architecture, approach, and design - $50k estimate
- Building data modeling automation - $50k estimate
- Building a DV load framework in your ELT process - min $150k estimate
2. Grundfos, the largest pump manufacturer in the world, uses Data Vault paired with Vaultspeed for their Data Catalogue product. It’s intended for internal use, reporting on commercial data, such as customers, sales, etc. It works like a library, you pick desired data points, press a button, and get a visual report. They reported that automating Data Vault through Vaultspeed saves them an estimated 4,800 hours over the life of the project.
3. Valipac, a Belgian packaging compliance company, needed to integrate decades of data and become more agile in managing changes in their systems. By adopting Data Vault (with Vaultspeed), Valipac successfully migrated 25 years of historical data from 8 different source systems into a new data platform in just 8 months. This resulted in 739 DV objects capturing their business. This was much faster than a traditional rebuild. The team was able to regain control over their data structure and enforce robust governance with unparalleled speed. Equally important, the new Data Vault is ready for the future.
4. WLTH, an Australian fintech startup offering digital lending and payment services, wanted a data infrastructure that could keep pace with new products and customer growth without a large data engineering team. They turned to Data Vault 2.0 and implemented it with Vaultspeed. The outcome was favorable: WLTH integrated data from 4 source systems and had their first Data Vault-generated code running in just 34 days. With only 1 in-house data engineer, WLTH was able to build a full-scale, cloud-based data warehouse on Snowflake using the DV approach. This has empowered WLTH to make faster data-driven decisions and even generate new analytics dashboards and reports on the fly for business users.
Is Data Vault Right for You?
If your organization deals with multiple data sources, frequent schema changes, compliance requirements, or long-term historical data, you’ll likely benefit from adopting Data Vault. And if you automate it, you can benefit even more.
Think of it this way:
- Star schemas are great to answer questions at a certain point in time
- Data Vault is great for building a system where those questions - and the data behind them can evolve safely and transparently over time.
Done right, Data Vault sets you up to move faster, with trust and less tech debt.
Final Thoughts
Data Vault provides an architectural answer to the challenges of modern data warehousing. It addresses the need to be scalable (handling ever-growing data), adaptable (ready for any source or change), and efficient (speeding up development through pattern-based design). For managers, directors, and VPs, overseeing data engineering and analytics, Data Vault offers a way to future-proof your data platform, build data products faster, and respond to changing business needs in an agile way, all while maintaining a single source of truth.