DataOps provides a Unified Control Plane to manage, observe and operate your modern data platform, delivering Data Products at the speed and scale your business demands.
Changing the way the world builds and manages data products
DataOps - the Data Product company - delivers productivity breakthroughs for data teams by enabling agile DevOps automation (#TrueDataOps) and a powerful Developer Experience (DX) to modern data platforms. The DataOps.live SaaS platform brings automation, orchestration, continuous testing and unified observability to deliver the Data Products you want at the speed the business needs. DataOps.live is a global company funded by Anthos Capital and Snowflake Ventures, with enterprise clients including Roche Diagnostics and OneWeb.
VaultSpeed + DataOps.live: improving the developer experience and creating more business value.
DataOps.live and VaultSpeed have partnered together to create a new and exclusive multi-layered automation solution for all the Snowflake customers. VaultSpeed’s best-in-class data warehouse automation combined with DataOps.live’s innovative orchestration and observability of the Snowflake environment, to help save precious time, and dramatically reduce risks to set up your Snowflake Data Cloud, to create more business value faster.
This solution aims to change and improve how people build and manage data products and data vaults on Snowflake’s single, integrated platform.
“We are excited to see this type of collaboration between our partners focused on delivering better-together solutions for our customers. DataOps.live and VaultSpeed are clearly committed to offering speed, scale, and efficiency to our joint customers.”
Tarik DwiekHead of Technology Alliances, Snowflake
Solution description and architecture
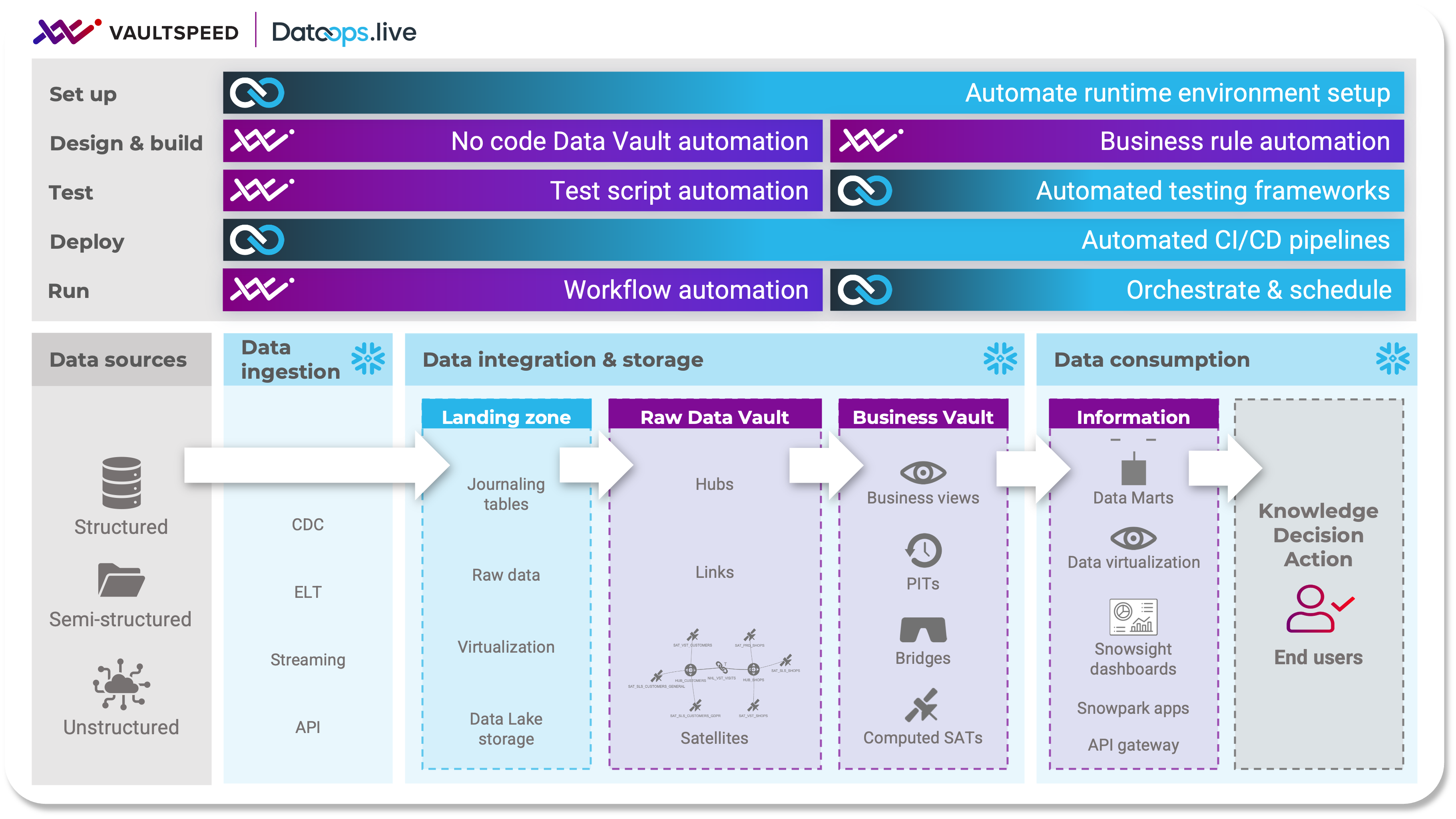
Setup: Automate your data environments and infrastructure with code. Snowflake has become the first fully programmable Data Cloud allowing companies to build code and configuration templates external to Snowflake and then “run” that code on the Snowflake Data Cloud. Build and rebuild environments with ease. React to failures with speed – rollback changes immediately without impacting the data – or recover from complete failures and rebuild in a fresh Snowflake tenant in minutes and hours instead of days, weeks, or months.
Design & build: You don’t need build your data model from scratch. VaultSpeed offers a consolidated Data Vault model based on the metadata we collect from your sources. You can modify that model using a comprehensive modeling interface to make it match your business needs. Built-in templates provide certified integration logic for Data Vault 2.0 and translate your data model into working DDL and ETL code that can be pushed into your CI/CD pipeline.
Test: VaultSpeed’s templating studio and rich metadata repository allow you to generate all necessary testing scripts that can be embedded into your regression testing framework. DataOps.live helps you run automated data regression testing to assure the quality of the flowing data at every point. Add metadata reporting to every data pipeline to monitor data quality KPIs over time.
Deploy: DataOps.live provides full environments build management for dev/test/prod/fb to support branch and merge gitflows. Standalone or fully mirror our backend git repository with your enterprise source code repository. Any number of developers can work independently in their own safe sandboxes without stepping on each other's toes, massively increasing developer efficiency.
Run: DataOps.live will help you leverage the power of advanced Orchestration capabilities for ALL your data integration and data movement platforms with enhanced connectors for your most popular tools. DataOps.live seamlessly imports the complex DAG routing flows and logic that VaultSpeed generates to ensure the Data Vault is loaded correctly, in the right order, while maximizing performance through parallel loading.