Kafka stream support
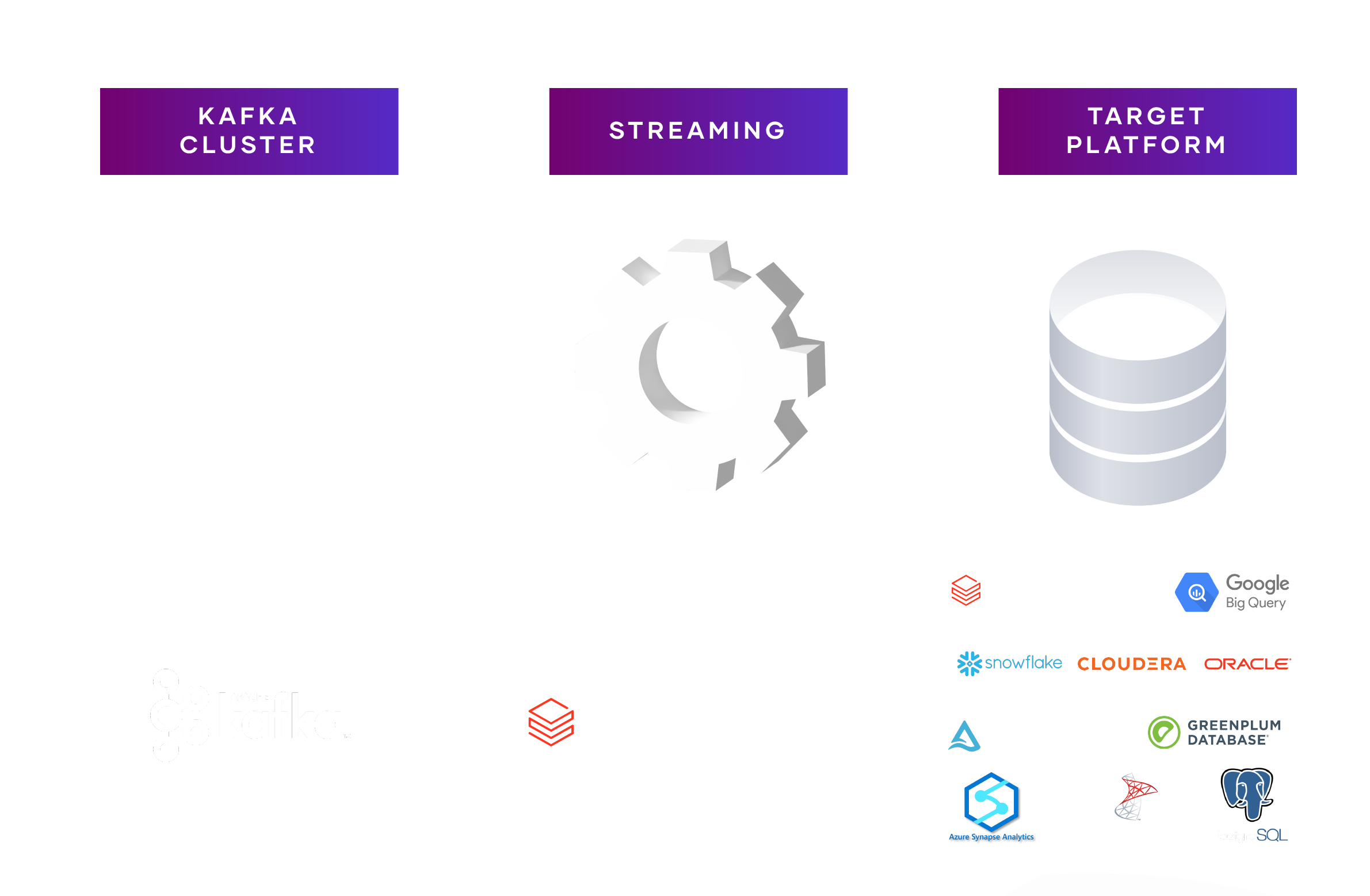
Say you have a lot of IoT data, trading data or inventory data coming in from Kafka topics. VaultSpeed Streaming would enable you to read the metadata from these topics, build a data vault model on top of them and stream the data straight into your Data Vault. Users can set up sources as streaming sources. For now, only Kafka streams are supported. VaultSpeed can read source metadata straight from the Kafka schema registry or from the landing zone where Kafka streams enter the data warehouse.
Same but different
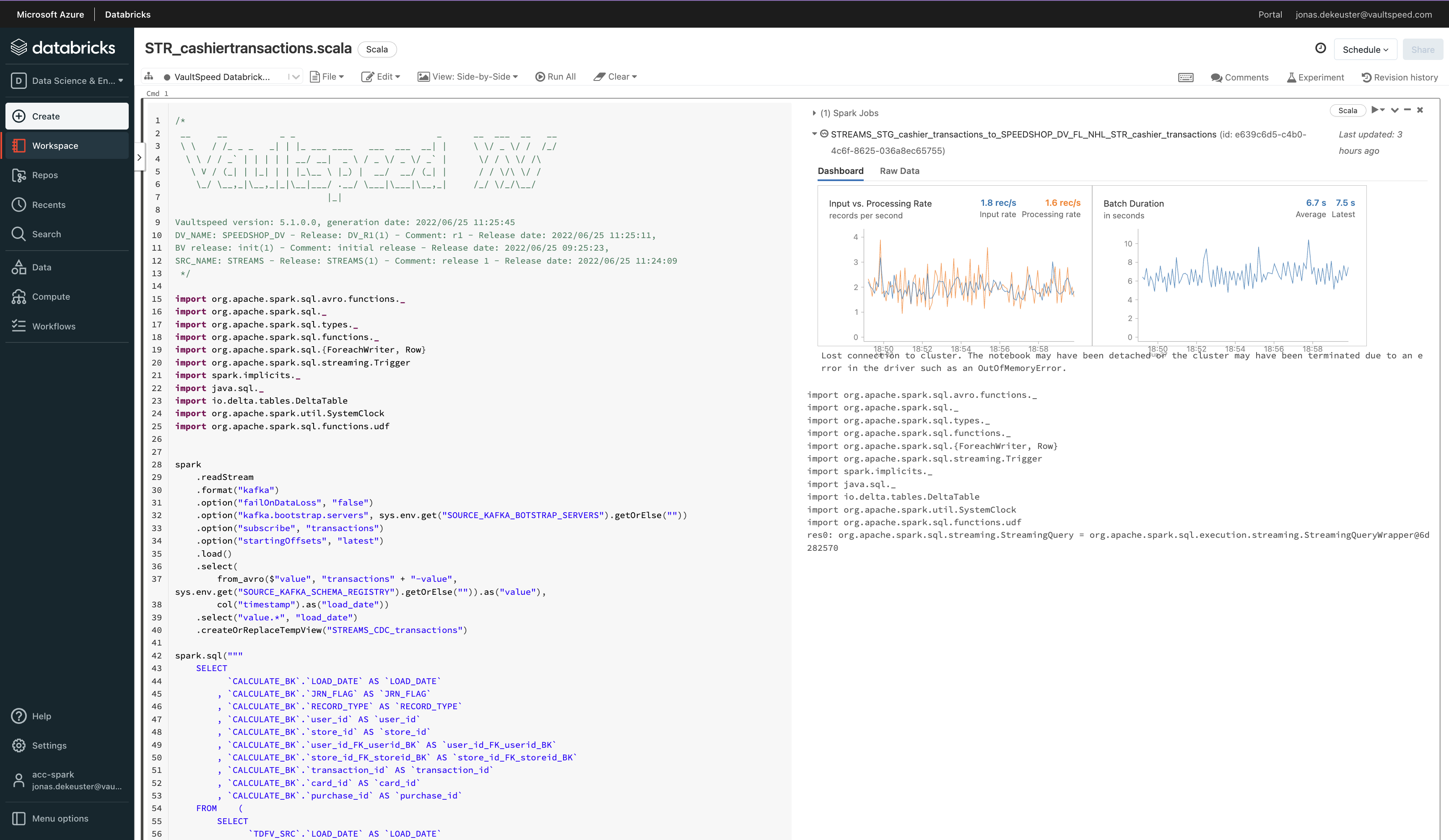
With Streaming, users can harvest metadata, configure sources and model Data Vaults. Just like they are used to for any other source type. Once the Data Vault model has been conceived, VaultSpeed will generate two types of code:
• Scala code to be deployed into your Databricks cluster becoming the runtime code.
• DDL code to create the corresponding Data Vault structures on the target platform.
For our streaming solutions, we only generate incremental logic. There’s no initial streaming logic since records are captured and processed sequentially: one record at a time. Initial loads, if necessary, can be executed using the standard initial loads. Identical to how we deliver on other source types.
The target for the Data Vault can be anything. Of course, you can choose to stay in Databricks, but any other platform that supports the JDBC protocol works as well. That implies that you could also use Azure Synapse, Snowflake, and many others as your Data Vault platform. To do so, we created a JDBC sink connector that handles the loading towards the target.
Going beyond the Lambda Architecture
VaultSpeed Streaming works in combination with all other source types, like CDC (Change Data Capture) and/or (micro)-batch sources. This allows customers to run their Data Vault at multiple speeds. At the same time, all data elements are available in the same integration layer regardless of the loading strategy you choose.