This year's first release takes Data Vault loading to another level. We introduce the ability to load streaming sources straight into the Data Vault objects. Other novelties include object-level CDC intervals, enhanced Spark SQL support, a fully integrated API reference, and a new hashing algorithm.
Spark Structured Streaming Support in Databricks (Release 5.0)
February 24th, 2022

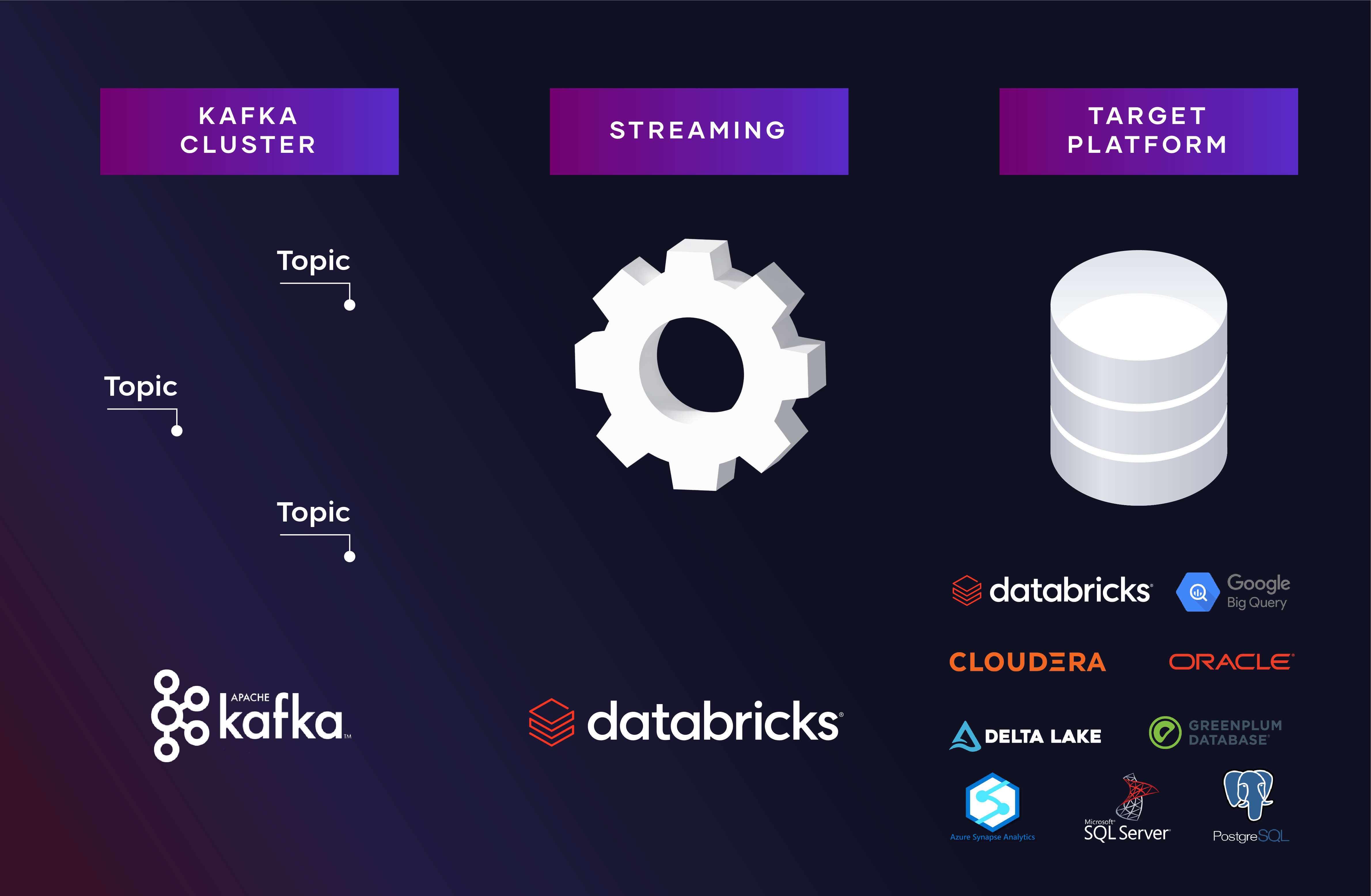
Spark Structured Streaming for Databricks
For all those struggling to integrate streaming data from numerous Apache Kafka topics, search no more:
We introduce support for Spark structured streaming on Databricks. The solution enables users to set up sources as streaming sources. At this stage, only Kafka streams are supported. VaultSpeed can read source metadata straight from the Kafka schema registry or from the landing zone where Kafka streams enter the data warehouse.
Same but different
Users can now harvest metadata, configure sources, and model Data Vaults. Just like they are used to for any other source type. Once the Data Vault model has been conceived, VaultSpeed will generate two types of code:
- Scala code to be deployed into your Databricks cluster
- DDL code to create the corresponding Data Vault structures on the target platform.
At runtime, messages will be read by Databricks from the Kafka topics, and they are transformed into a Data Vault structure. The loading logic handles short-term data delivery issues such as latency and long-term issues like missing keys in the source system or downtime. Currently, Databricks is the only platform we support to host the runtime of the streaming solution.
For our streaming solutions, we only generate incremental logic. There is no initial streaming logic since records are captured and processed sequentially: one record at a time. Initial loads, if necessary, can be executed using the standard initial loads. Identical to how we deliver on other source types.
The target for the Data Vault can be anything. Of course, you can choose to stay in Databricks, but any other platform that supports the JDBC protocol works as well. That implies that you could also use select Azure Synapse, Snowflake, and many others as your Data Vault platform. To do so, we created a JDBC sink connector that handles the loading towards the target.
Going beyond the Lambda Architecture
Our streaming solution works in combination with all other source types, like CDC (Change Data Capture) and/or (micro)-batch sources. This allows customers to run their Data Vault at multiple speeds. At the same time, all data elements are available in the same integration layer regardless of the loading strategy you choose.
Object-based CDC loading interval
We have always pushed hard to provide market-leading support for the best-of-breed CDC tools. CDC is great for when you need to equip your Data Vault with high loading performance and minimal impact on source systems. In release 5.0, this improved even more: Our SRC to STG mappings now support object-specific CDC loading windows. As a result, you can set up your CDC source to load different objects using independent loading windows, ensuring you never miss a change in your source.
We are introducing two new parameters to improve the FMC (Flow Management Control) logic for loading windows:
The ‘OBJECT_SPECIFIC_LOADING_WINDOW’ parameter ensures that each source object has its own loading window and should be used in combination with the existing parameter ‘FMC_DYNAMIC_LOADING_WINDOW’.
The ‘CDC_BASED_LOADING_WINDOW’ parameter allows for the end date of the loading window to be determined by the maximum available CDC timestamp of the object. This ensures that all data gets loaded, provided that it arrives in chronological order. Using this setup can resolve syncing issues between CDC data delivery to the target and the loading schedule.
Enhanced Spark SQL support: Databricks
In release 4.2.4, we started supporting Databricks as a target, enabling our customers to run their Data Vault in the Databricks data lakehouse. In release 5.0, we enhanced support for all Spark SQL targets by adding new capabilities like end dating.
Spark SQL mapping in Databricks
VaultSpeed API
We released our completely redesigned API in 4.2.6. We remain in a closed beta phase with this release, but we added an embedded API reference to our user interface. All endpoints are elaborately explained and since you are already authenticated in the app, you can start experimenting with the API right away.
Our API will become generally available in the next release.
API reference embedded in VaultSpeed UI
No Hash
Last but not least, we added another hash option to create all key elements in your Data Vault: ‘NO_HASH’. This option will not hash anything and instead leave the input as a concatenated string containing your business keys and business key delimiters. Some target databases (Azure Synapse, Greenplum…) prefer this option as it allows for better distribution of table rows across different compute nodes.

NO_HASH parameter
More info can be found in the Change Log.
Read more

