
Automated data transformation
Automated Data Transformation (ADT) streamlines the data delivery process by automating data conversion, manipulation, and restructuring.
This reduces manual work in creating a data warehouse, lakehouse, or mesh, and enhances data quality, ultimately facilitating better decision-making.
Handling multiple data sources
ADT involves gathering vast amounts of source metadata and remodeling it to render it suitable for analysis, reporting, LLM ingestion, or other downstream applications that bring business value.
The outcomes of ADT include physical data structures (DDL), data transformations (DML), and orchestration workflows. The more metadata that can be processed, the more automated the process becomes.
Delivering cloud productivity
Cloud data platform vendors, such as Snowflake, Databricks, Microsoft, and Google, have created environments that enable the effortless creation of data infrastructure with limitless scalability.
However, productivity is unattainable without automation. Analysts estimate that the average enterprise organization has 115 different data sources. Forget about attempting to clean, format, aggregate, and integrate data from all these sources manually.
The missing link in the automation chain
Tools such as Fivetran, Airbyte, and several others cover the transfer of data from source systems to the data cloud with minimal coding and an almost fully automated setup.
Analytics platforms like Looker, Alteryx, and C3.ai make life of business users easier by automating reports and using artificial intelligence to help them find answers to their questions.
Smart automation of data transformation was considered undoable in the past, given the uniqueness of each company's business context and data stack. Until now.
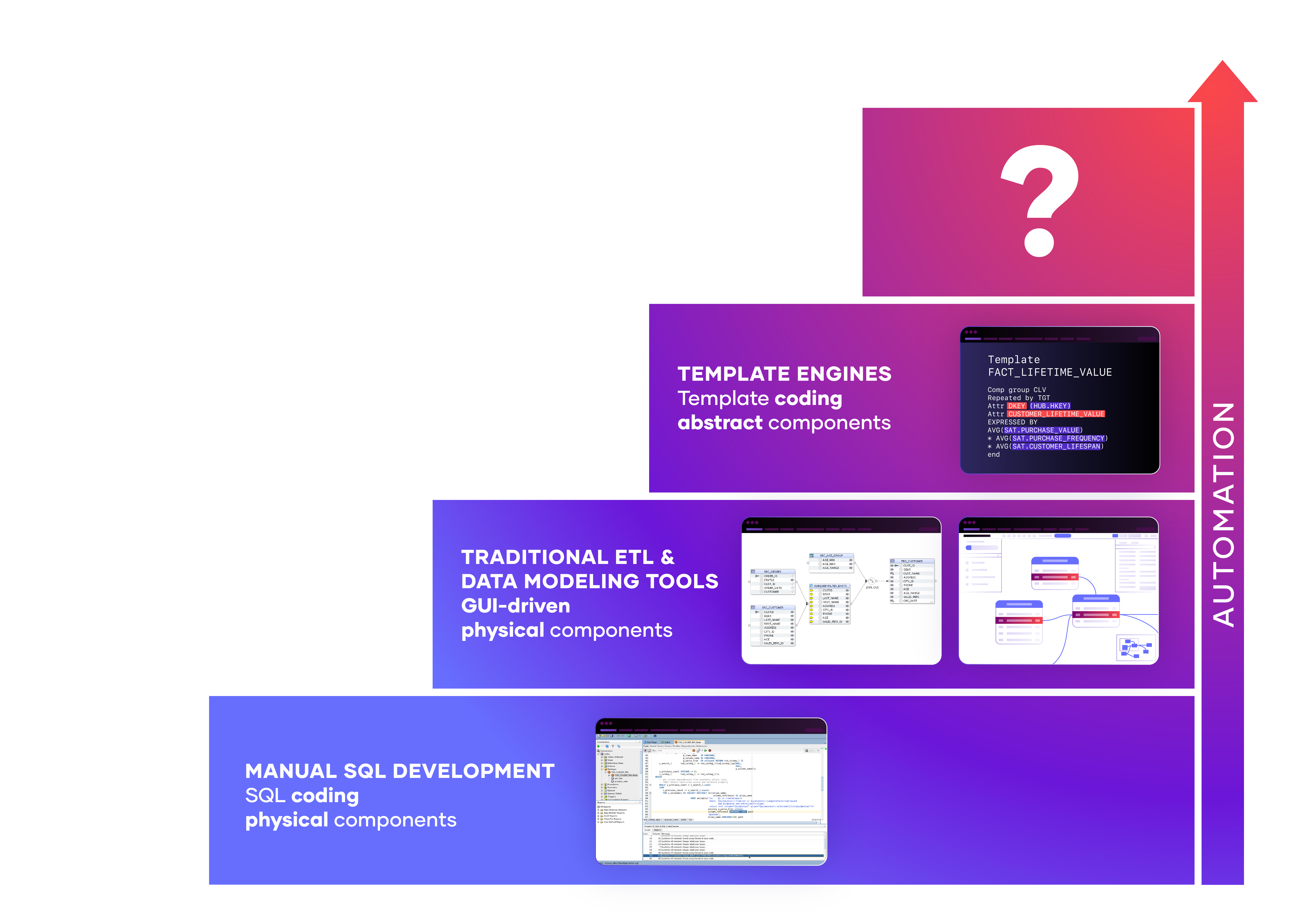
Four generations of data transformation solutions
Automated data transformation represents the fourth-generation data transformation solution that fundamentally changes what data teams can deliver.
First generation: manual coding
Not so long ago, data teams were manually coding DDL and DML SQL statements using physical data runtime components like tables, attributes, and keys. This laborious task was error-prone and cumbersome.
Second generation: traditional ETL/ELT tooling
Traditional ETL/ELT tools allowed for the automation of SQL code by providing the engineers with a drag-and-drop GUI to manipulate physical data runtime components using common SQL operators like a join, filter, aggregate or lookup. The physical data runtime components were harvested and stored in a metadata repository.
Despite this progress, there was still a need to manually build every data mapping and a separate data modeling tool was often needed as well. This was acceptable for a smaller volume of transformation jobs, but proved impractical for larger tasks involving 500 to 1000 mappings a week.
Third generation: template engines
The insight surfaced that automated data transformation is only achievable at a certain level of abstraction, not at the detail level. Data automation requires repeatable patterns.
Once identified, repeatable source-to-target transformation patterns could suddenly be automated. Patterns to load a staging table, patterns to load a Data Vault hub, patterns to load a fact table, and so forth.
Data engineers eagerly started coding these abstract data transformation patterns to automate more data layers. But template coding is still coding: it is prone to error that becomes exponential fast. A template error does not repeat once, it repeats 500 to 1000 times. If you’re not careful, you rapidly descend into a path of data error automation.
What remains missing?
Fourth generation: Automated Data Transformation
The fourth generation of data transformation, as exemplified by VaultSpeed, reintroduces the metadata repository and GUI.
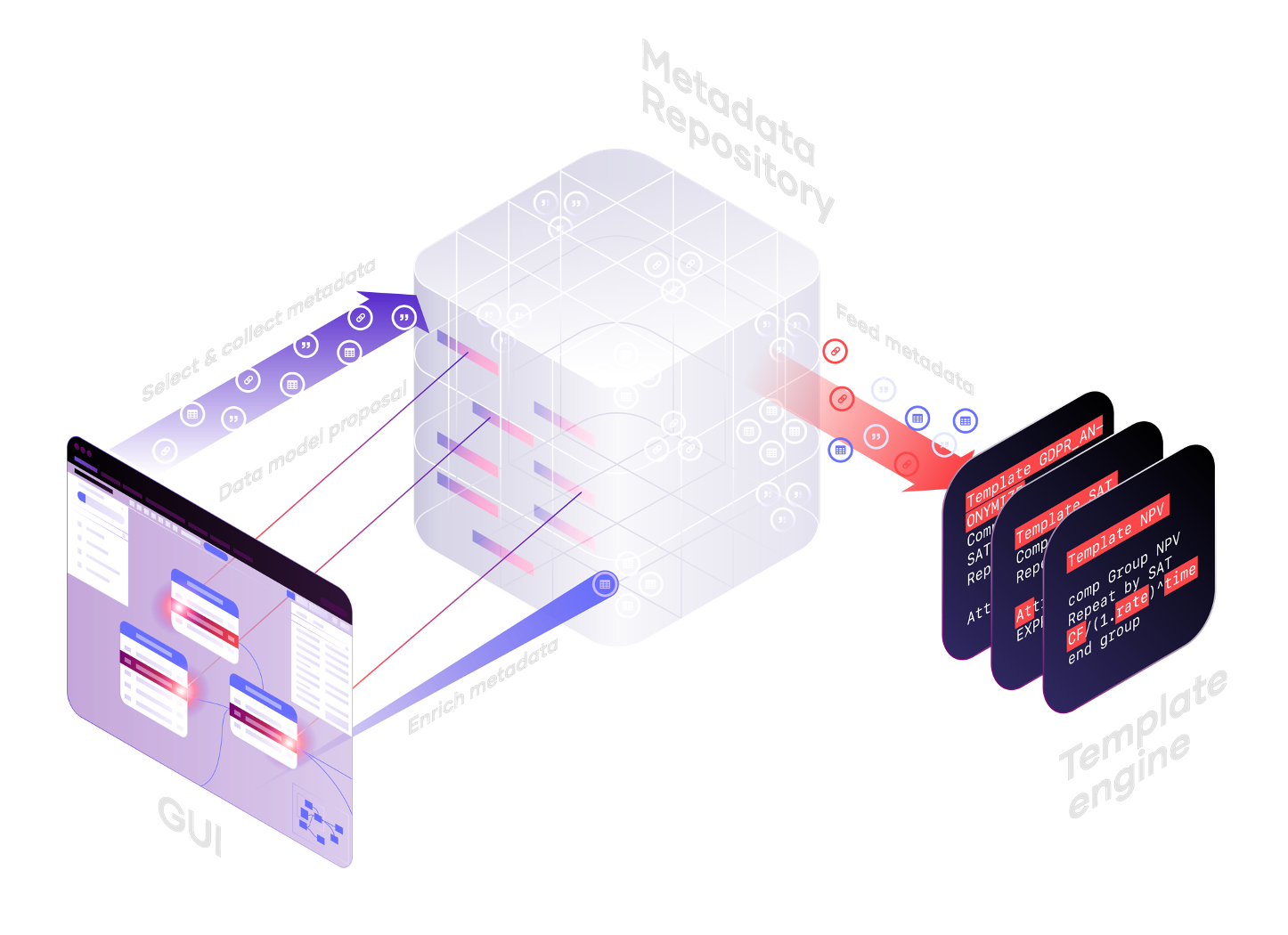
This is primarily because the template engine comes with pretested, pre-built automation templates that eliminate the need for data engineers to engage in template coding.
The metadata repository stores metadata, including abstract signature components and their relationships. It features a smart rule engine that analyzes source metadata to suggest a target data model, a significant time-saving feature.
Data engineers have a GUI to view and customize the data model based on their business needs by tagging key entities and attributes with the right signature types.
These applied signature tags connect the entire metadata set to the automation templates, effectively bridging the gap between physical and abstract metadata.
The metadata is processed through the template engine, transforming the source data model into the target data model while simultaneously providing the transformation code that can be implemented in the physical data runtime.
One could perceive this as ETL at the abstract level, employing abstract signatures instead of physical data components. Welcome to the world of abstract ETL.
Don't compromise
More business value
ADT involves gathering vast amounts of source metadata and enriching it to make it suitable for analysis, reporting, LLM ingestion, or other downstream applications that bring business value.
Speed & Efficiency
The results of ADT are physical data structures (DDL), data transformations, and orchestration workflows. The more metadata that can be processed, the more automated the data integration process becomes, making it faster and more efficient.
Increased data quality
By automating data transformation, businesses can ensure that their data is accurate, consistent, and easily accessible, which in turn leads to better decision-making.
Increased agility
Enterprise companies frequently change data sources, tools, models, or other architectural elements to keep up with rapidly evolving markets. ADT is engineered to adapt to these changes without rework and it plays a crucial role in converting data into a relevant format that has business value today and in the future.
AI readiness
LLMs deliver better results when trained on the reliable data input that automated data transformation provides.