Template subquery support
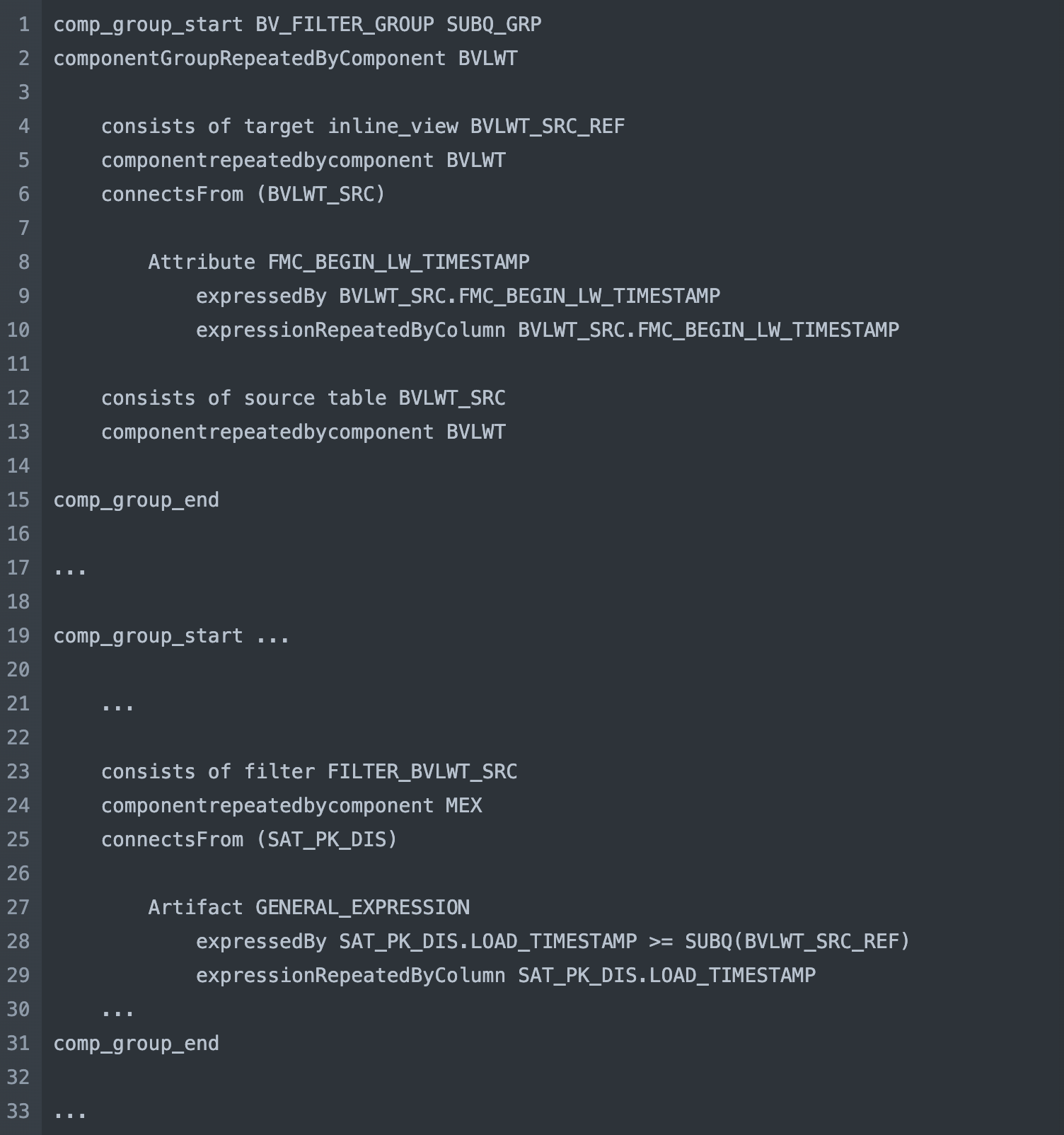
We are excited to announce that our template language now supports subqueries in expressions! This new feature allows you to create a component group of type SUBQ_GRP, which functions like a CTE with an INL_V_GRP. Once you have created your subquery component group, you can easily reference it in other component groups by using the syntax SUBQ() in your expressions. However, please note that subqueries can only be used within expressions and not as source or join components.
For instance, you can use subqueries in the WHERE clause to filter query results based on conditions derived from other tables or aggregated data. This can include scenarios like comparing values to averages, filtering based on existence or non-existence in related tables, and selecting records based on specific criteria like departmental associations or order dates.
We hope you find this new addition to our template language helpful!
Improved links-across-sources loading performance
The primary objective of constructing an enterprise-wide data warehouse or lakehouse is to facilitate the integration of data from multiple sources. Links across sources (LAS) are essential for creating exploration links between different sources, offering an additional way to integrate and explore data from various sources.
In the graphical editor, we can select entities from various sources and their respective releases. Once we add the selected objects to the canvas, we can establish relationships between objects from different sources. It's worth noting that foreign objects are displayed in a different color and their source name is mentioned in their object name. LAS objects are deployed into the Business Vault layer.
In version 5.6.2, we significantly improved the loading performance of LAS and LNA mappings. Our team has enhanced the loading logic, substantially increasing the LAS loading performance on Databricks. Additionally, BigQuery and Synapse have also experienced reduced load times. Moreover, we have identified and fixed a bug in Snowflake that caused out-of-memory errors in the LNA mapping for large Satellites when data from multiple sources was loaded into the Business Vault.
Renamed FK detection
At times, source systems tend to change the names of foreign key relationships which can be quite frustrating. This issue typically arises while integrating systems with system-generated FK names. Earlier, if a primary or foreign key in the source was renamed, VaultSpeed would add the renamed key as a new one and disable the old one. Such changes can have an adverse impact on the resulting integration model.
In version 5.6.2, we have added a new feature that allows automatic recognition of any changes in the name of primary or foreign keys in the source model. As a result, the key name in VaultSpeed’s metadata repository will be automatically updated without any manual intervention. This update will eliminate the need for any manual adjustments to the model.
Other changes
We made the following updates:
- Improved the Business key ordering screen to make it more intuitive.
- The application now displays a warning message at the top of every page a few hours before a maintenance window. Any running tasks will be automatically canceled during maintenance and resumed afterward.
- Fixed the default data type mapping for Numeric in Snowflake. It now properly retains the sizes as defined in the source.
- Fixed an issue with type conversion in the SAT Hash Difference calculations when data quality is bad.