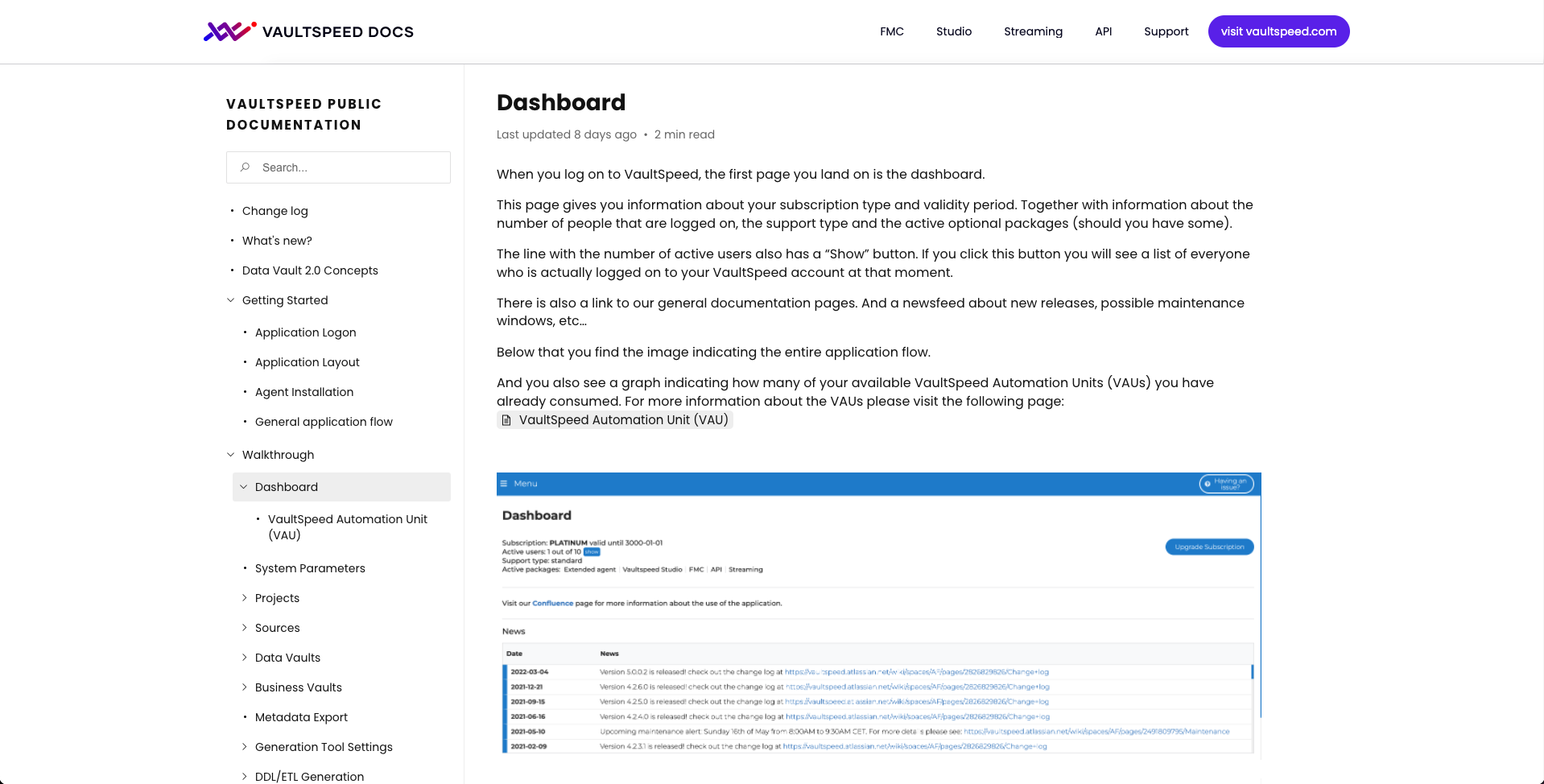
VaultSpeed version 5.1 went live over the weekend. It includes: a major functionality boost to our source editor; the general availability of our REST API; Azure Data Factory support for Databricks; and a sequence-based incremental loading implementation. All that and a new docs portal too.
Source object split, ADF for Databricks & API (Release 5.1)
May 16th, 2022

Source object split
Source models are never perfect. These are some issues that occur frequently and make data modeling more complex:
- file sources contain flattened structures where business keys and relations are tangled up in a single file
- objects are categorized differently, and in different taxonomy ranks, in sources and in the target
- relationship tables appear in the source without a separate structure for the business key
These issues might well make it necessary, at some point, to remodel the source and split a source object. Our source editor now offers this functionality.
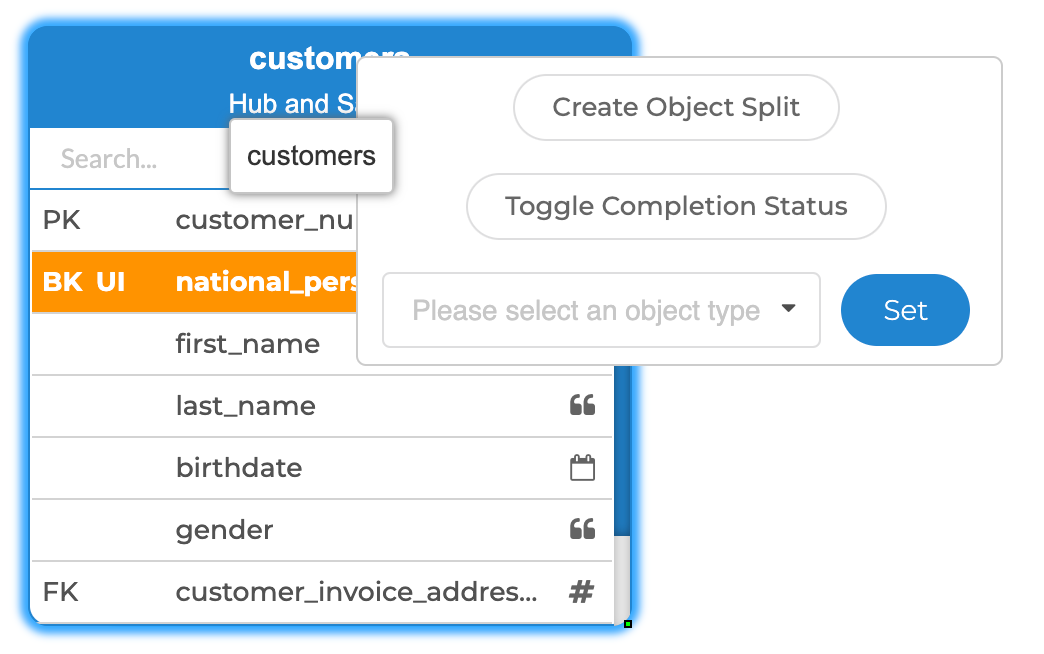
Object splitting means dividing source objects into one or multiple entities. Users simply need to select which columns, keys and relationships they want to include in a split object. They can also add filter conditions to distribute data across split objects. For example, to direct persons and companies (both being customers) to separate business entities.
Create source object split
Source splitting allows for modeling objects towards the right level of granularity before integrating them in the Data Vault model. That includes (re-)normalizing a flattened file, shifting the target model towards a lower taxonomy rank or setting up links without breaking the unit of work.
Split objects will behave like any other objects throughout the remainder of the Data Vault modeling process: to use them in hub groups, for example, or to set different object types, build new relations with other objects, etc. Read more in our docs portal.
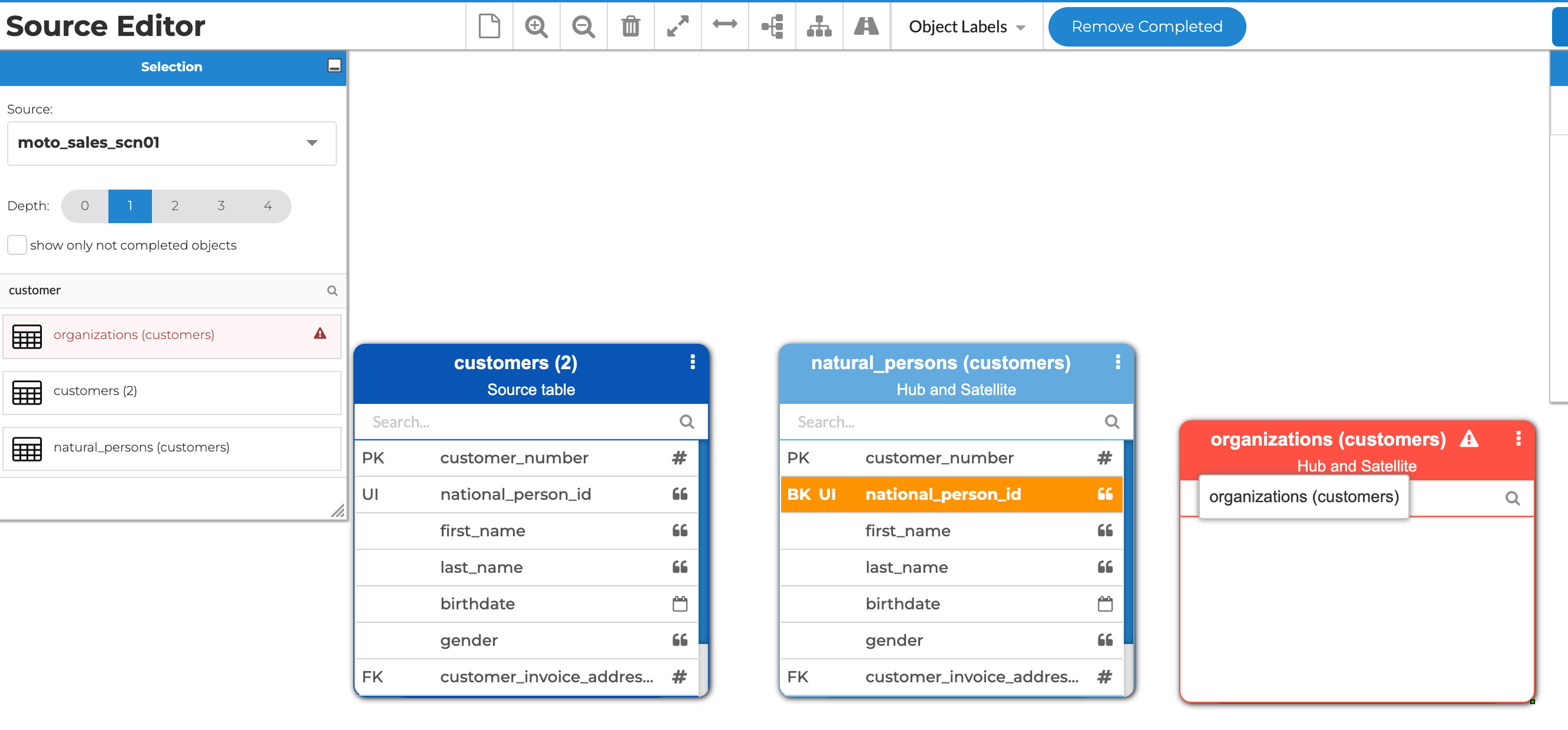
Object split in the source editor
Aligning the Data Vault model with the correct level of the business taxonomy is important for achieving better results. At VaultSpeed, we tend to put a lot of emphasis on this. By adding the split feature, we now support upward as well as downward classification from source to target.
- Upward: Do you want to build your Data Vault model at a higher taxonomy level than the source model? Create a hub group.
- Downward: The source model is built at a higher taxonomy level than the desired level for the Data Vault model? Just split the object.
Read more about business taxonomy mapping in the Data Vault.
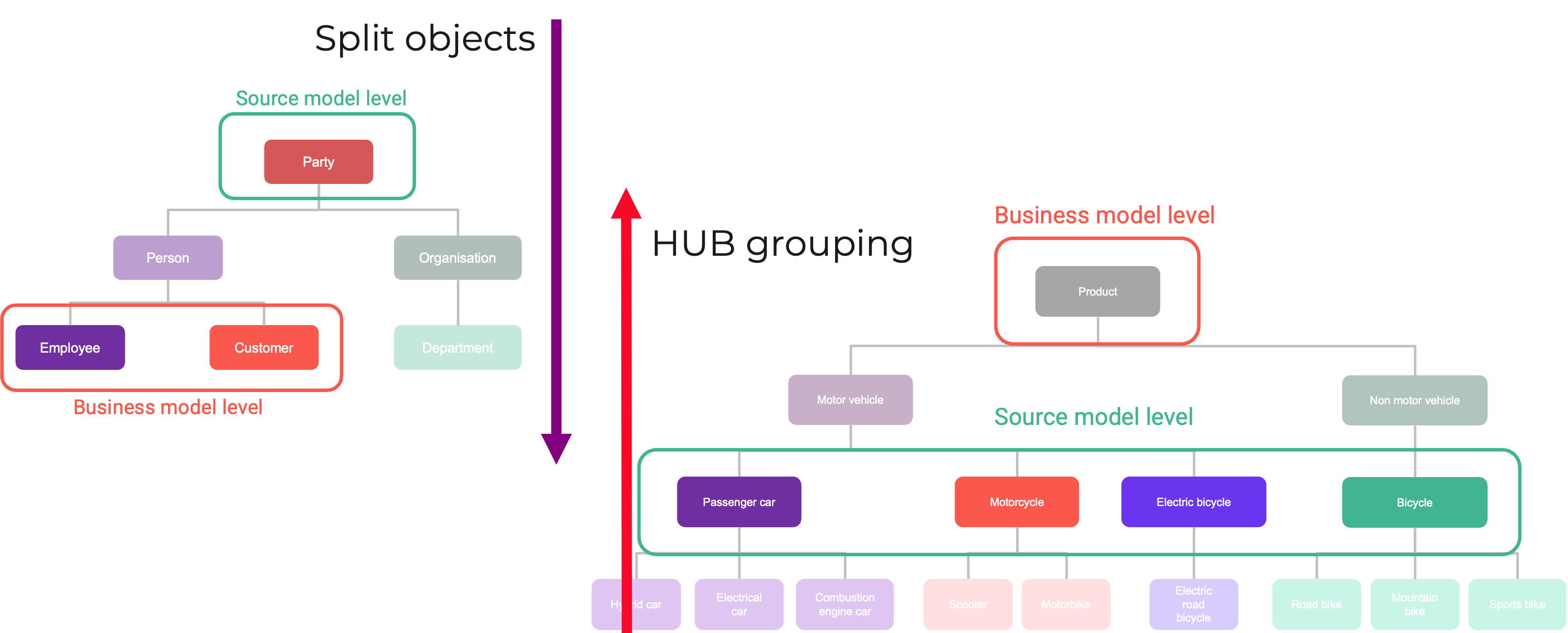
Business model mapping options
Source splits will be executed in the pre-staging layer. This ensures flexibility in case users want to change existing splits or add new ones on top of the same source entities. Splits have the option to deduplicate records. This is particularly useful for normalizing a flattened file structure. For example, splitting the country or city object from the addresses source file.
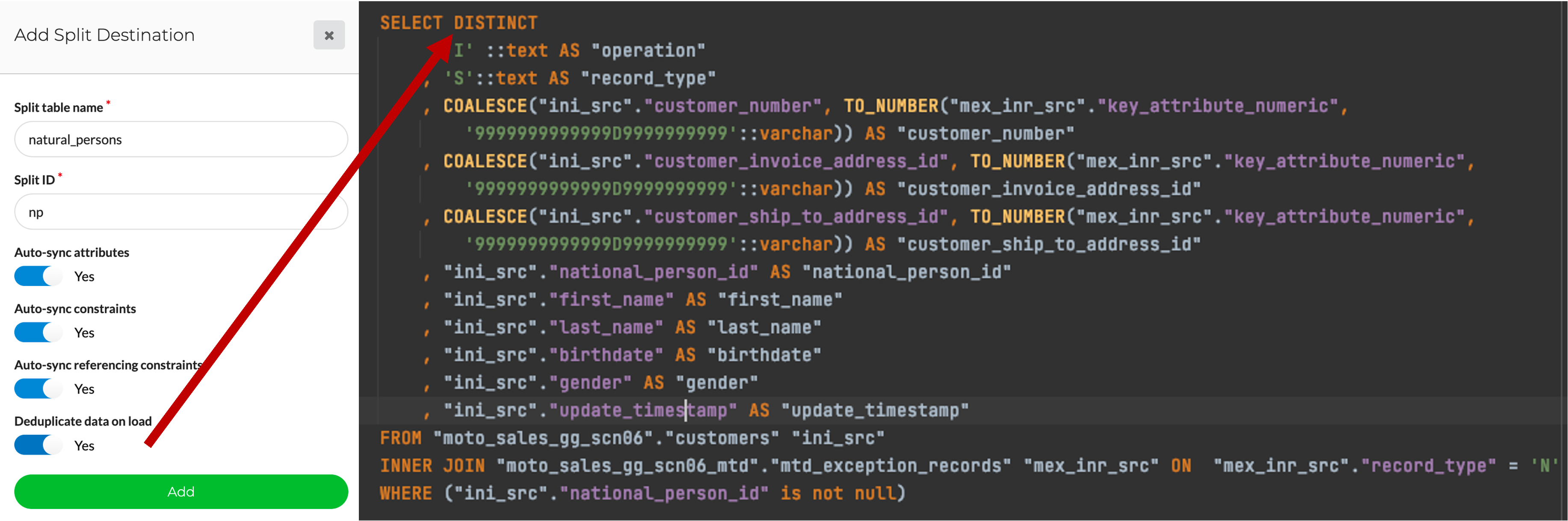
Setting a parameter directly influences the generated code for the object split
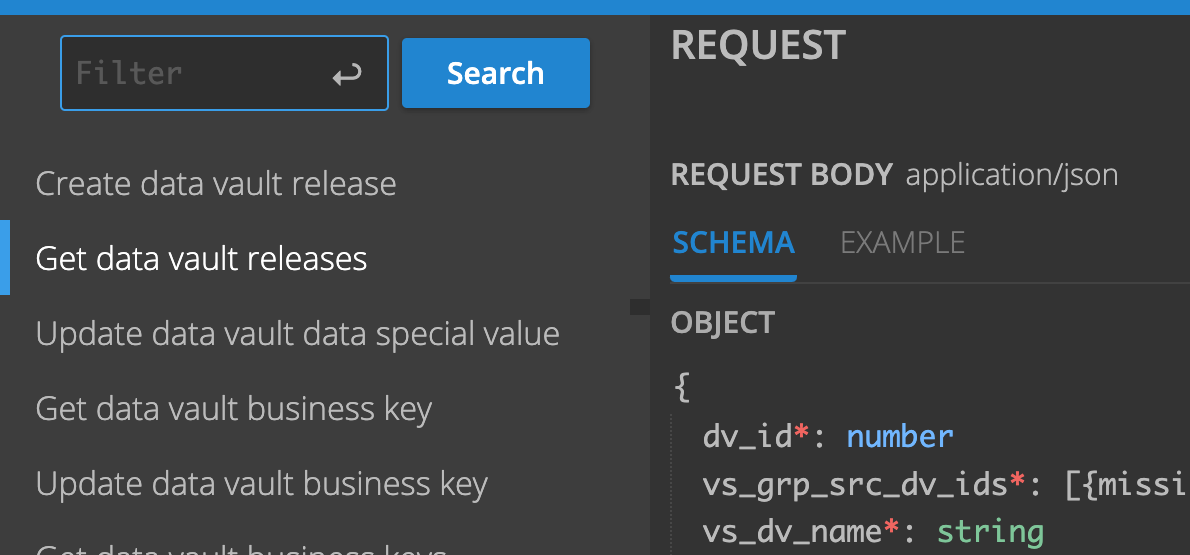
General availability deployment of REST API
We completely redesigned our REST API in our previous release, 4.2.6. After running in beta release since the end of last year, we are now making it generally available to all our customers.We embedded the API reference into VaultSpeed’s frontend. This enables the testing of more than 350 endpoints without requiring authentication, since users are already securely logged in to the application.
More information on the API can be found in our completely revamped docs portal.
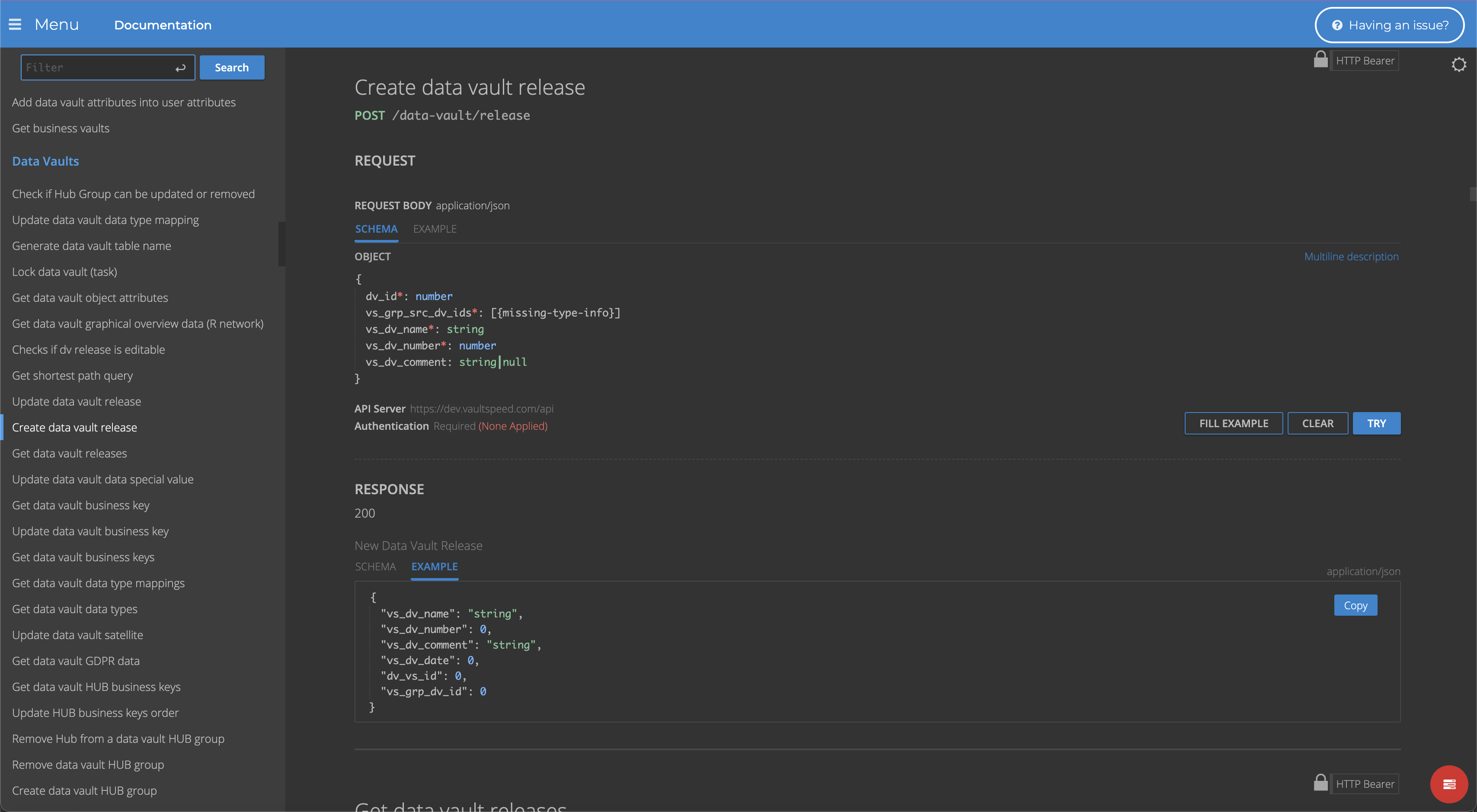
API reference docs are embedded in VaultSpeed
Azure Data Factory support for Databricks
We added support to use ADF as the scheduler for Databricks. It makes sense because Databricks is available on the Azure cloud marketplace and therefore part of the same ecosystem as ADF. Users need to set up a linked service in their Data Factory account using a secure access token that they can generate in Databricks.
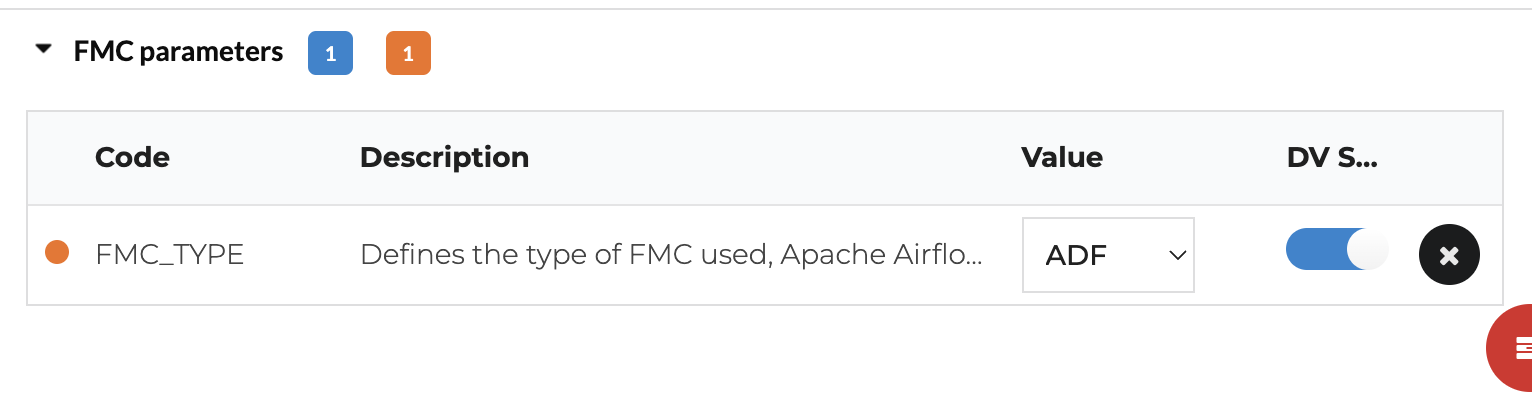
ADF for Databricks parameter
To start generating workflows, you’re required to set ADF as the FMC type for your Data Vault. Only grouped flows are supported, and mappings in each group will be executed in parallel. The concurrency set in VaultSpeed defines how many groups there are.
To control concurrency within Databricks, you create an environment variable in the cluster named FMC_CONCURRENCY and set that equal to the desired number of parallel executions per group.
To set up autodeploy, add connection details for ADF and your Databricks environment in the VaultSpeed agent config file.
New Airflow plugin for Snowflake
We continuously keep track of the latest upgrades of the tools we integrate with. Customers loading their Snowflake warehouse using Apache Airflow are strongly advised to upgrade their existing Airflow plugin before generating any new workflows. We made performance improvements and increased the overall robustness of the data flow. More information on how to update the plugin can be found in our docs portal.Sequence-based incremental loading
Diverse sources require an array of different loading options. We added another CDC type: the modification sequence.
This option can be used in cases where source objects deliver changed records with a sequence number (instead of a modification date) indicating the order of the changes. Source systems like SAP often use this sequence number setup for changes.
You just need to set the column name that contains the sequence – VaultSpeed will take care of all the rest.
This new CDC type can be used together with CDC_BASED_LOADING_WINDOW to load only the latest changes by keeping track of the last loaded sequence number.
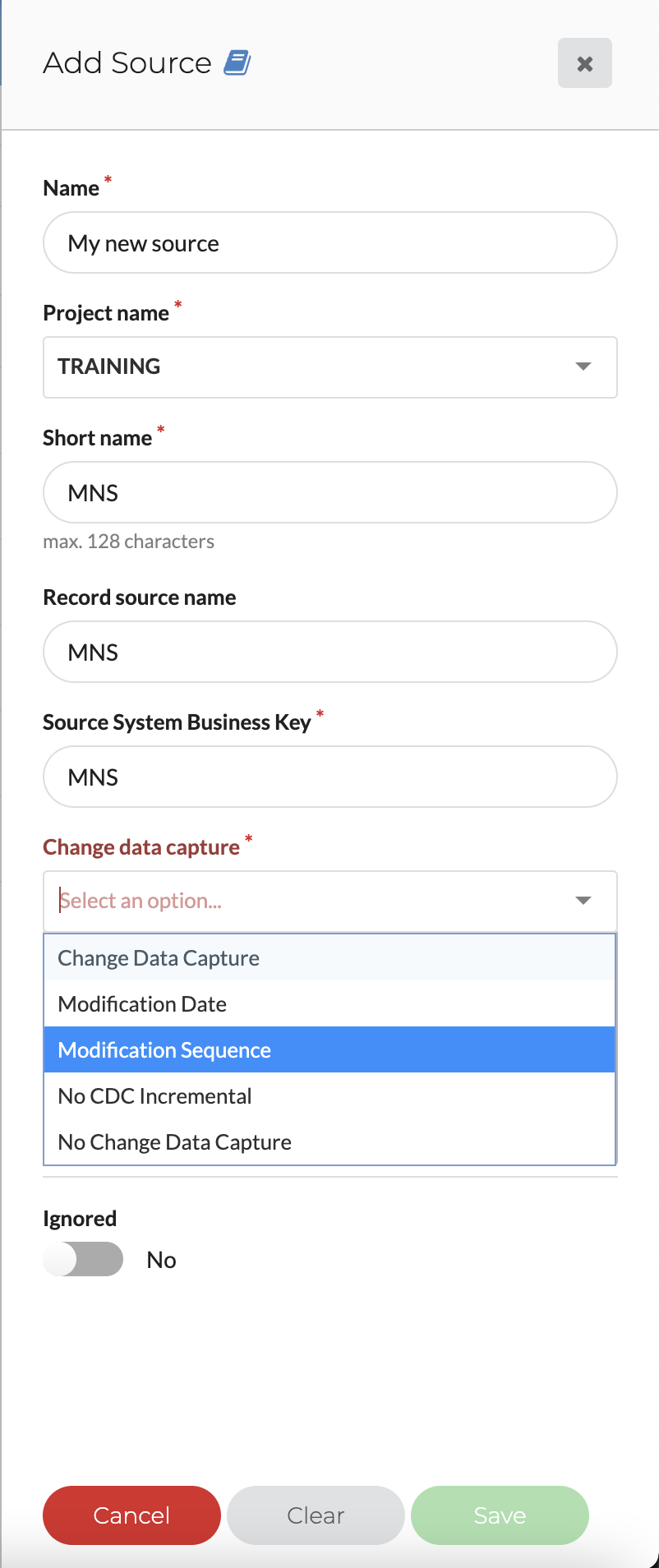
Choose your preferred CDC option
New docs portal
Last but not least, we’ve completely revamped our docs portal to provide customers with better guidance on how to use our DWH automation tool.
You’ll find more reading material, better structured, and with improved search functionality.
Make sure to check it out and see what’s new in VaultSpeed.
VaultSpeed Docs