Lakehouse Platform combining the best elements of data lakes and data warehouses.
Databricks Lakehouse Platform
The Databricks Lakehouse Platform combines the best elements of data lakes and data warehouses to deliver the reliability, strong governance and performance of data warehouses with the openness, flexibility and machine learning support of data lakes.
With a lakehouse, you can eliminate the complexity and expense that make it hard to achieve the full potential of your analytics and AI initiatives.
How VaultSpeed can integrate with Databricks
Data Vault is well suited to the lakehouse methodology
The goal of Data Vault modeling is to adapt to fast-paced changing business requirements and support faster and agile development of data warehouses by design. A Data Vault is well suited to the lakehouse methodology since the data model is easily extensible and granular with its hub, link and satellite design so design and ETL changes are easily implemented.
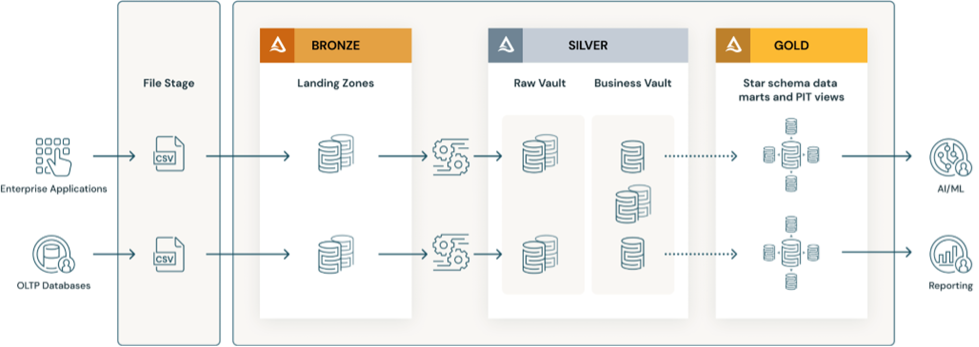
Databricks Bronze, Silver & Gold layers
Data Vault modeling recommends using a hash of business keys as primary keys. Databricks supports hash, md5, and SHA functions out of the box to support these primary keys.
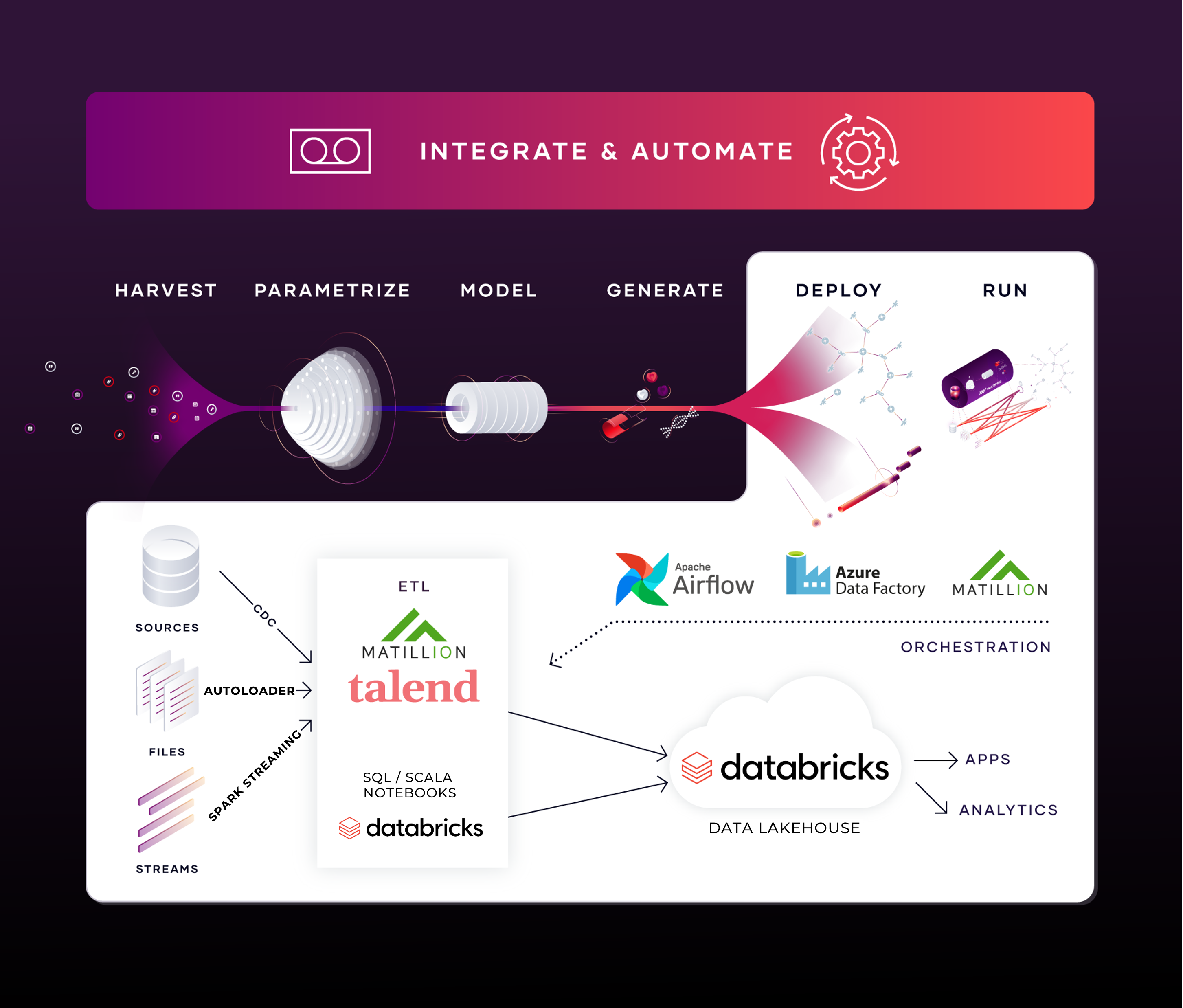
VaultSpeed Data Vault automation
VaultSpeed helps you to model the Data Vault and delivers the data structures and the ETL needed for data loading.
The tool blends both data-driven and model-driven approaches:
ingest metadata from the source to speed up the modeling process
incorporate the business model to build a Data Vault model that resembles your business
VaultSpeed’s data architecture is very closely related to the bronze-silver-gold setup proposed by Databricks.
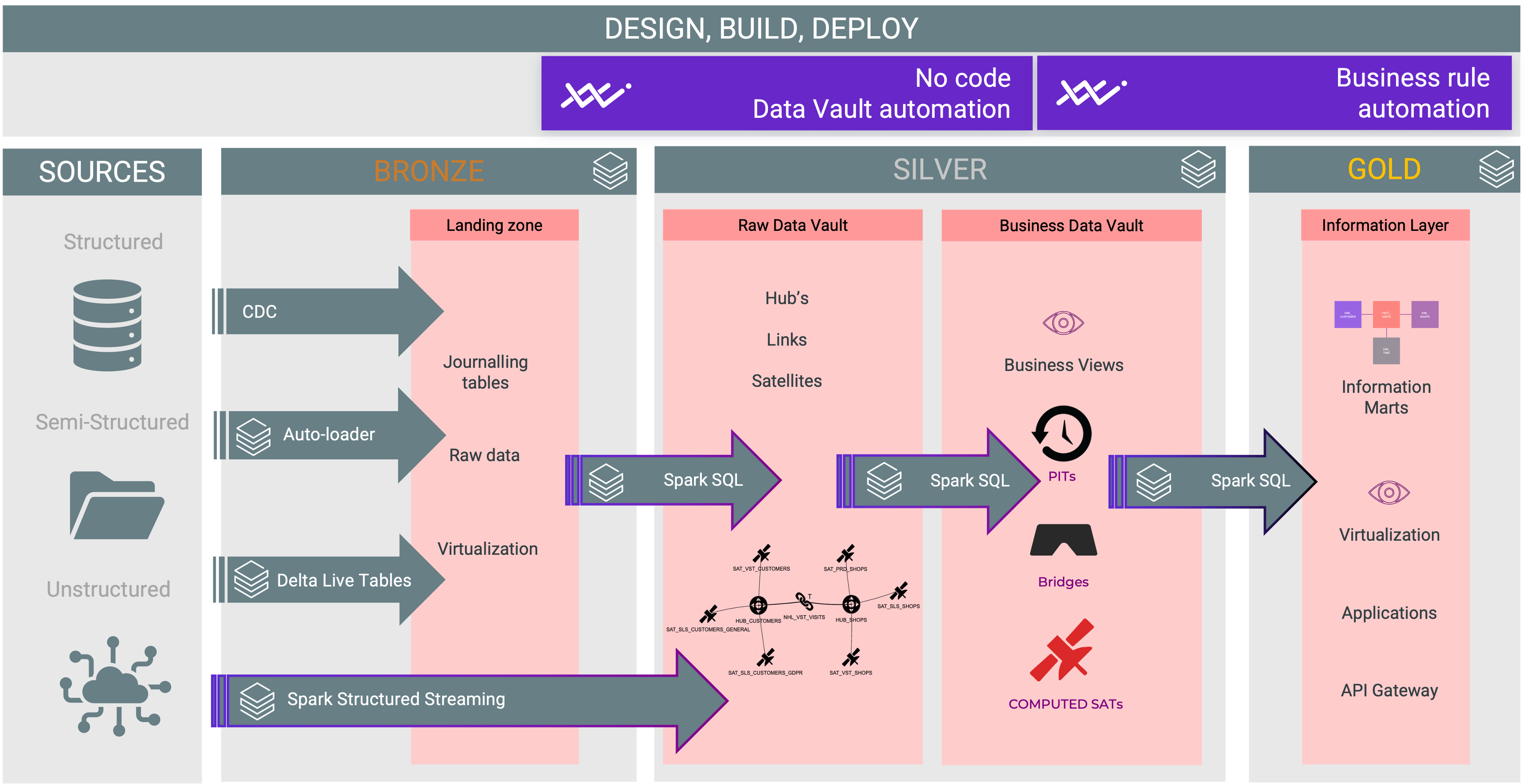
Reference Architecture
For Bronze & Silver, VaultSpeed brings you no-code Data Vault automation. Data Vault is a pattern that works, no need to break it.
As for the Gold layer, the structure can be anything, from star schemas to flattened tables. VaultSpeed’s Template Studio luckily allows you to code almost any use case.
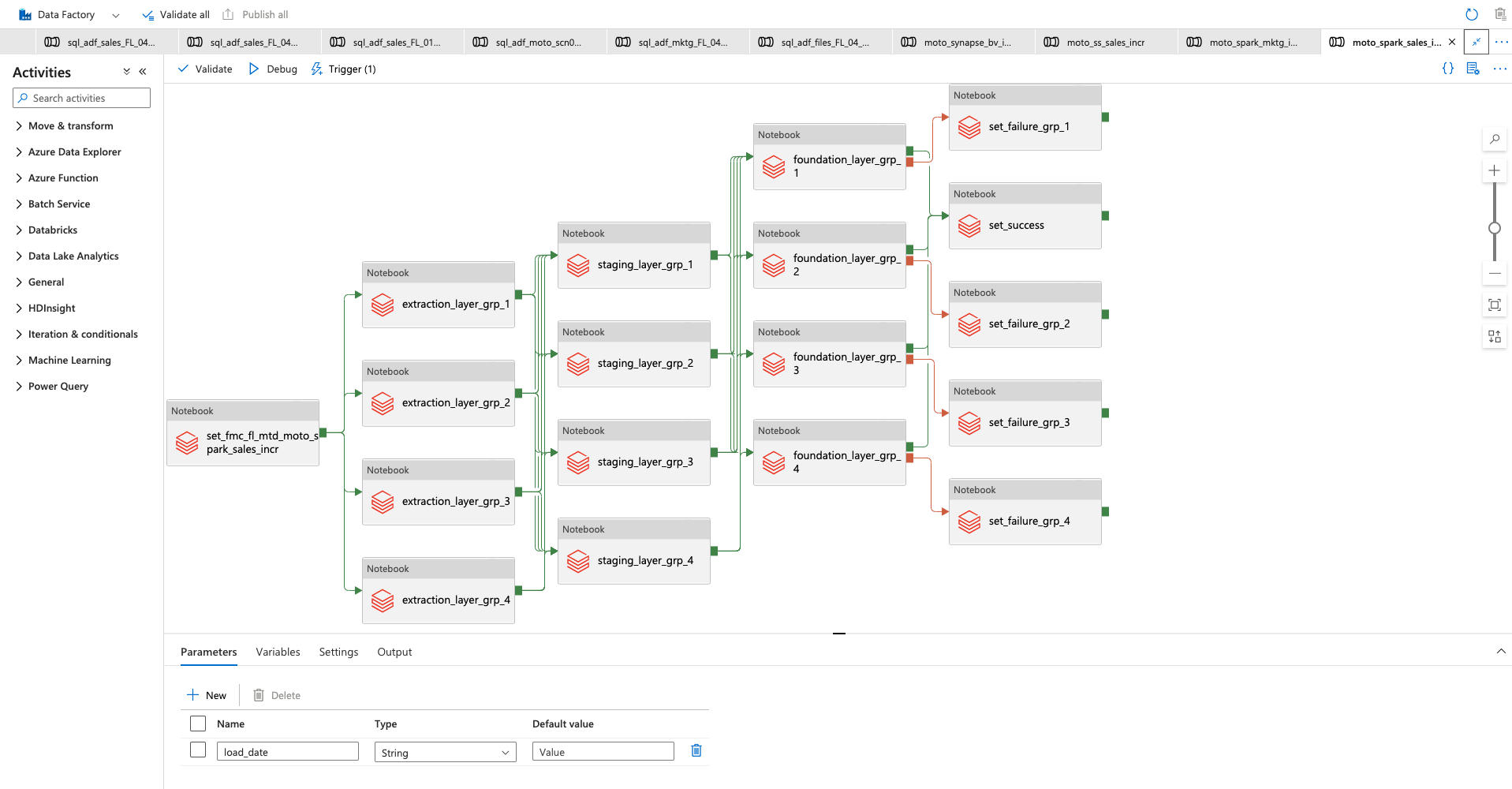
Create workflow schedules
Use VaultSpeed’s flow management control (FMC) add-on module to ensure that all data pipelines are executed at the right time, and in the right order. Deploy and schedule your workflows in best-of-breed schedulers like Azure Data Factory or Apache Airflow.
ADF for Databricks
A solid foundation for analytics
First things first: to build data products, you need data. VaultSpeed helps you to get your data into the lakehouse continuously. Now you can run state-of-the-art analytics to help answer the complex end-to-end questions that drive better business decisions. When specifications change, you only need to rebuild and reload your data in the analytics or application area, while the Data Vault layer safely collects and stores all the data you need.
Streaming Data Vault
VaultSpeed’s Streaming add-on module enables you to stream data into your Data Vault using Spark Structured Streaming. VaultSpeed — out of the box — supports conventional solutions for loading data from source to target. Multiple flavors of batch and CDC loading are available. But if conventional data loading isn’t enough for you, VaultSpeed will generate two types of code:
Scala code to be deployed into your Databricks cluster becoming the runtime code.
DDL code to create the corresponding Data Vault structures on the target platform.