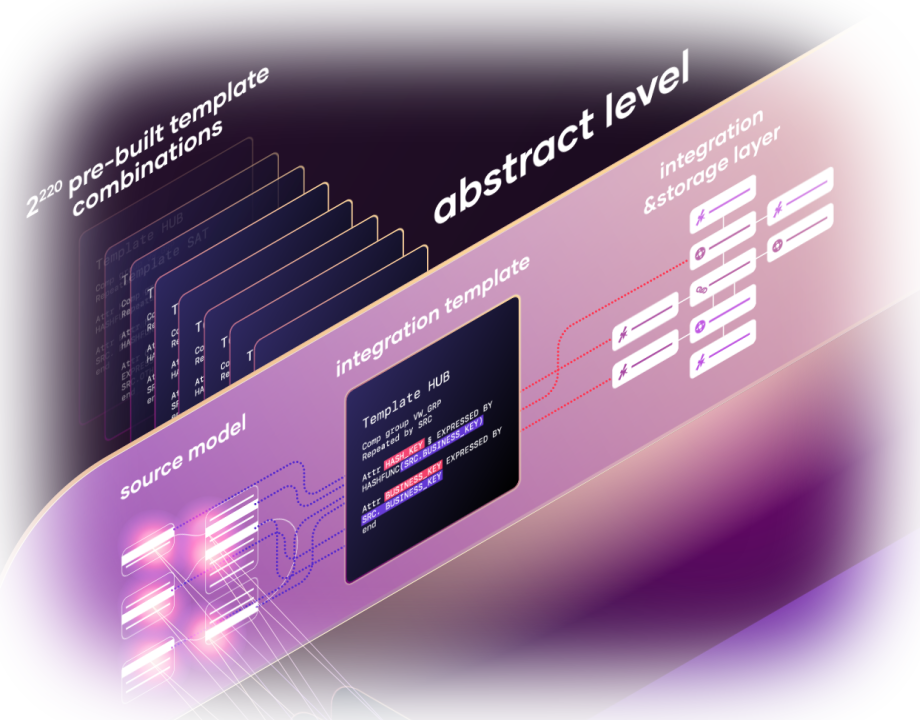
3. Integration template application
Applying our template code to translate logic into DDL and ETL instructions.
Learn more
7 STEPS TO FASTER DELIVERY
SEE HOW IT’S DONE
Automated data integration
Delivering unparalleled automation for designing and developing your data integration layer

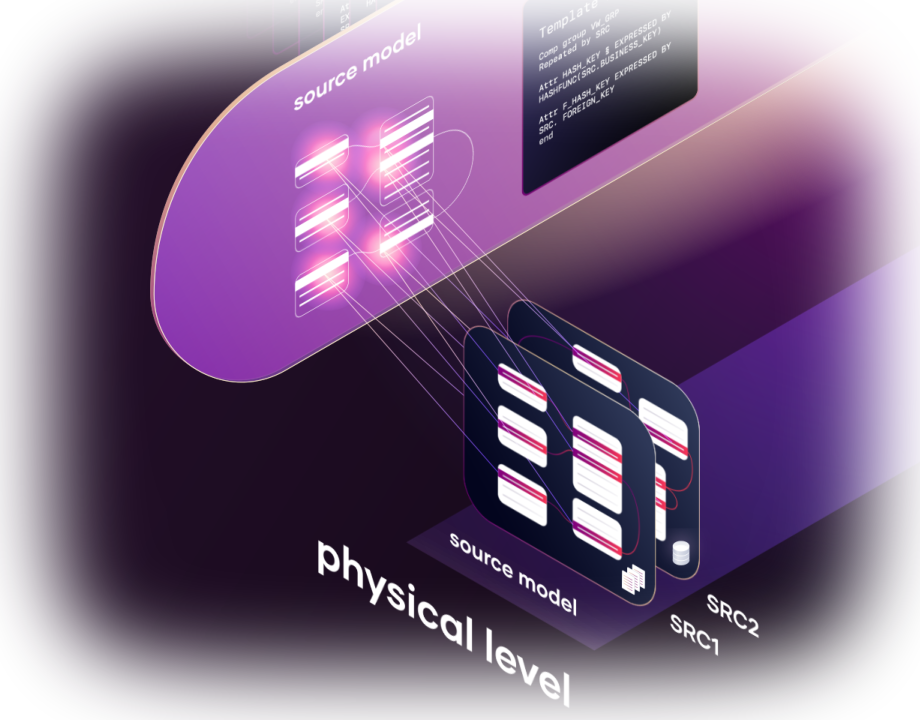
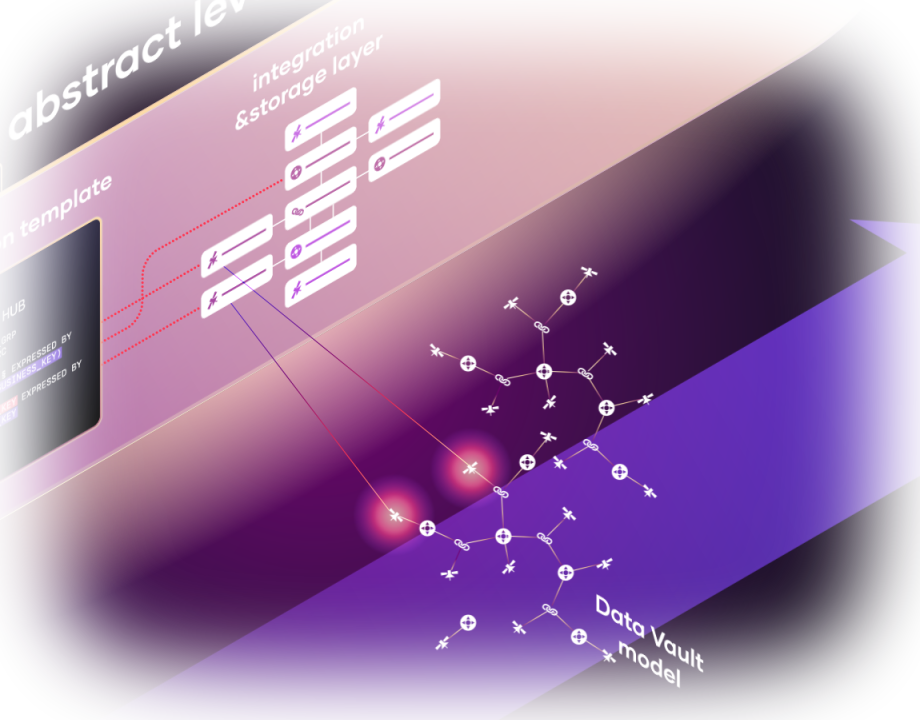
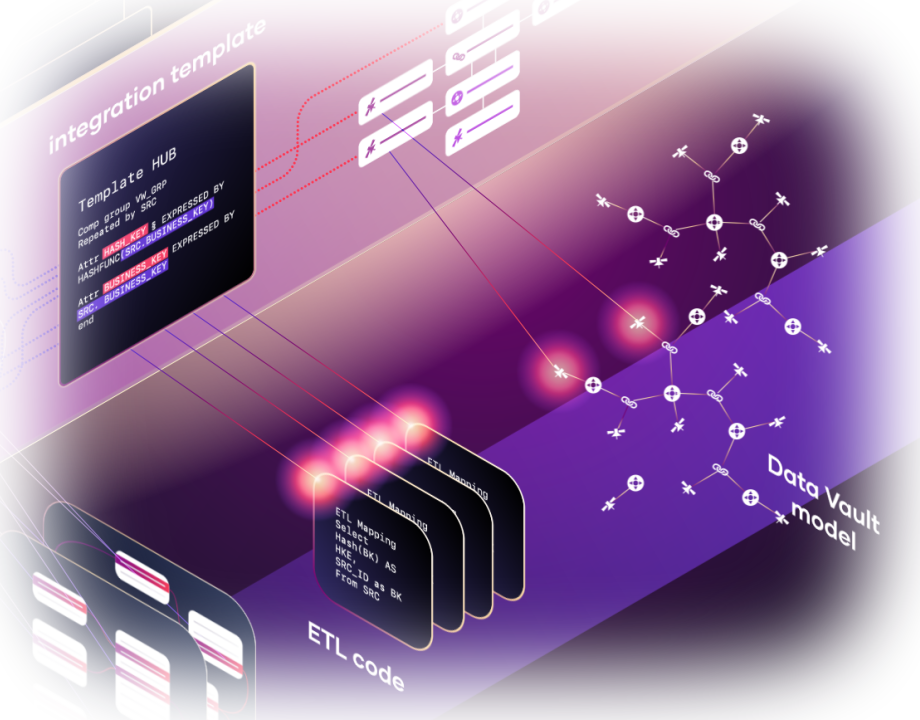
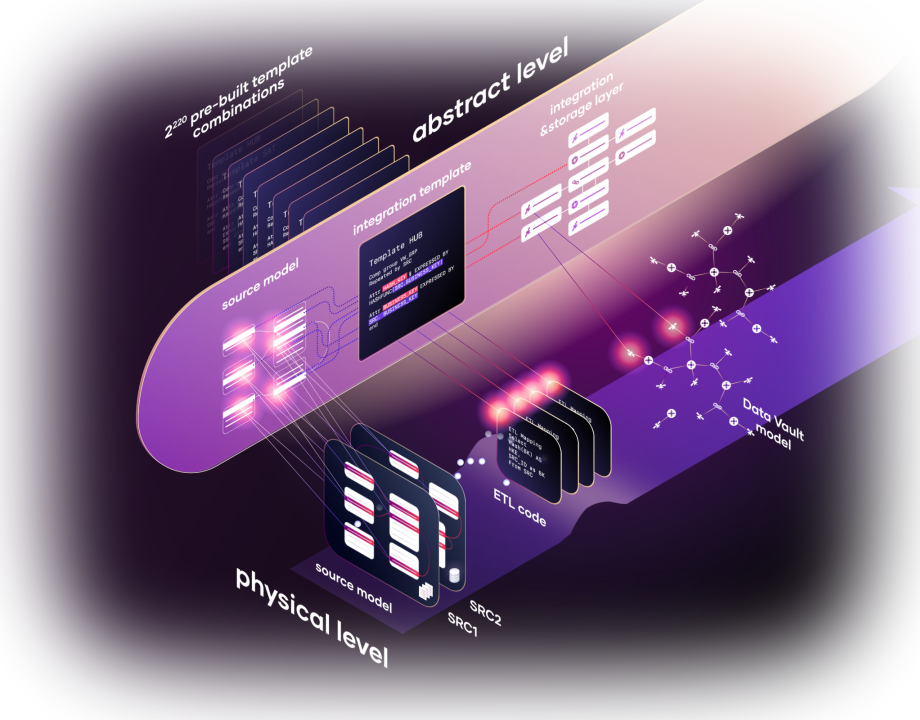
Learn about VaultSpeed’s business logic automation
Tech stack integration
VaultSpeed fits with your sources & other tools. No need to replace.
Integrations
Ready to start?
Deploy your data warehouse or lakehouse faster, without the stress.