The VaultSpeed automation tool delivers both initial and incremental load mappings and workflows.
It doesn’t matter whether our customers have a change data capture (CDC) solution or not. We support all kinds of data delivery to the DWH.
February 8th, 2022

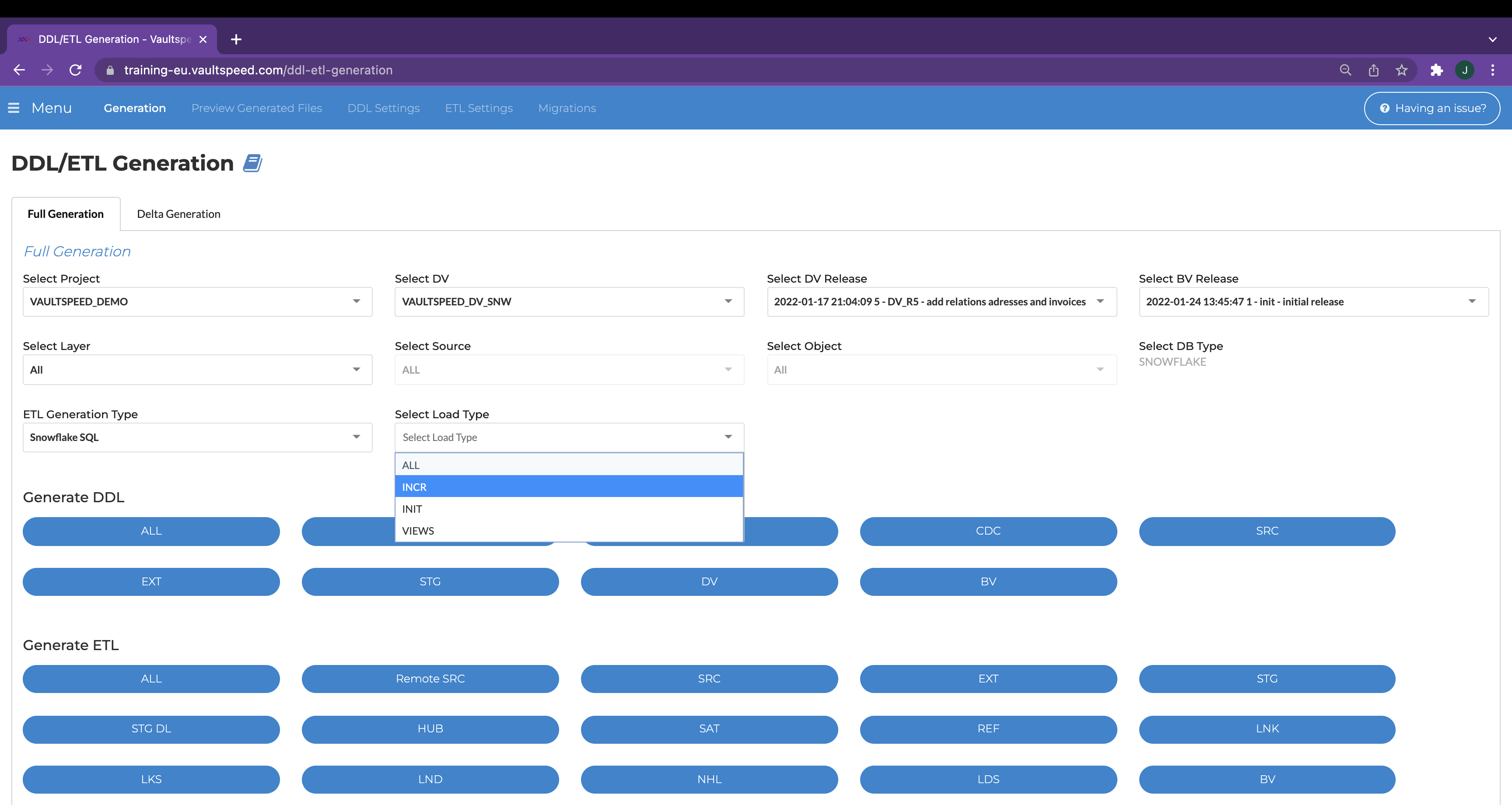
The VaultSpeed automation tool delivers both initial and incremental load mappings and workflows.
It doesn’t matter whether our customers have a change data capture (CDC) solution or not. We support all kinds of data delivery to the DWH.
The initial load – the first time a source system is loaded into the Data Vault – copies the entire set of data. This set can consist of files, source tables, external tables, database dump files, etc. Our initial loads use the INI schema, which is automatically created for our customers. The loading logic for any initial loads is pretty straightforward since there is no previously loaded data to consider. Initial loads are tailored for substantial loading volumes.
After the initial data loading takes place, it’s necessary to dump the delta between the target and source data at regular intervals. Incremental data loading of the newly added or modified data can be based on any type of incremental data delivery: CDC, files or source journaling tables. Incremental loading logic takes care of all dependencies and specifics when data is already loaded in the DWH.
Our incremental loads have a built-in solution to handle loading windows. Loading windows will vary in size based on the loading frequency. The incremental loads are tuned for batch and micro-batch loading performance.
VaultSpeed incremental loads also allow for a firewall that prevents loading duplicate events. These
occur during reloading of loading windows that were already processed or when there are server time mismatches. Duplicates are filtered out based on keys and source timestamp.
Data flows are prone to system failures. A server can crash, network connections can drop. Therefore, restartability is another essential feature of both our initial and incremental loading. All our flows contain the logic to ensure you can restart them upon failure with no data loss.
For our streaming solutions, we only generate incremental logic. There’s no initial streaming logic since records are captured and processed sequentially: one record at a time. Initial loads, if necessary, can be executed using the standard implementation.